时间序列
本用户指南部分概述了流式表达式和数学表达式中可用的一些时间序列功能。
时间序列聚合
timeseries 函数利用 Solr 的内置分面和日期数学功能执行快速、分布式的时间序列聚合。
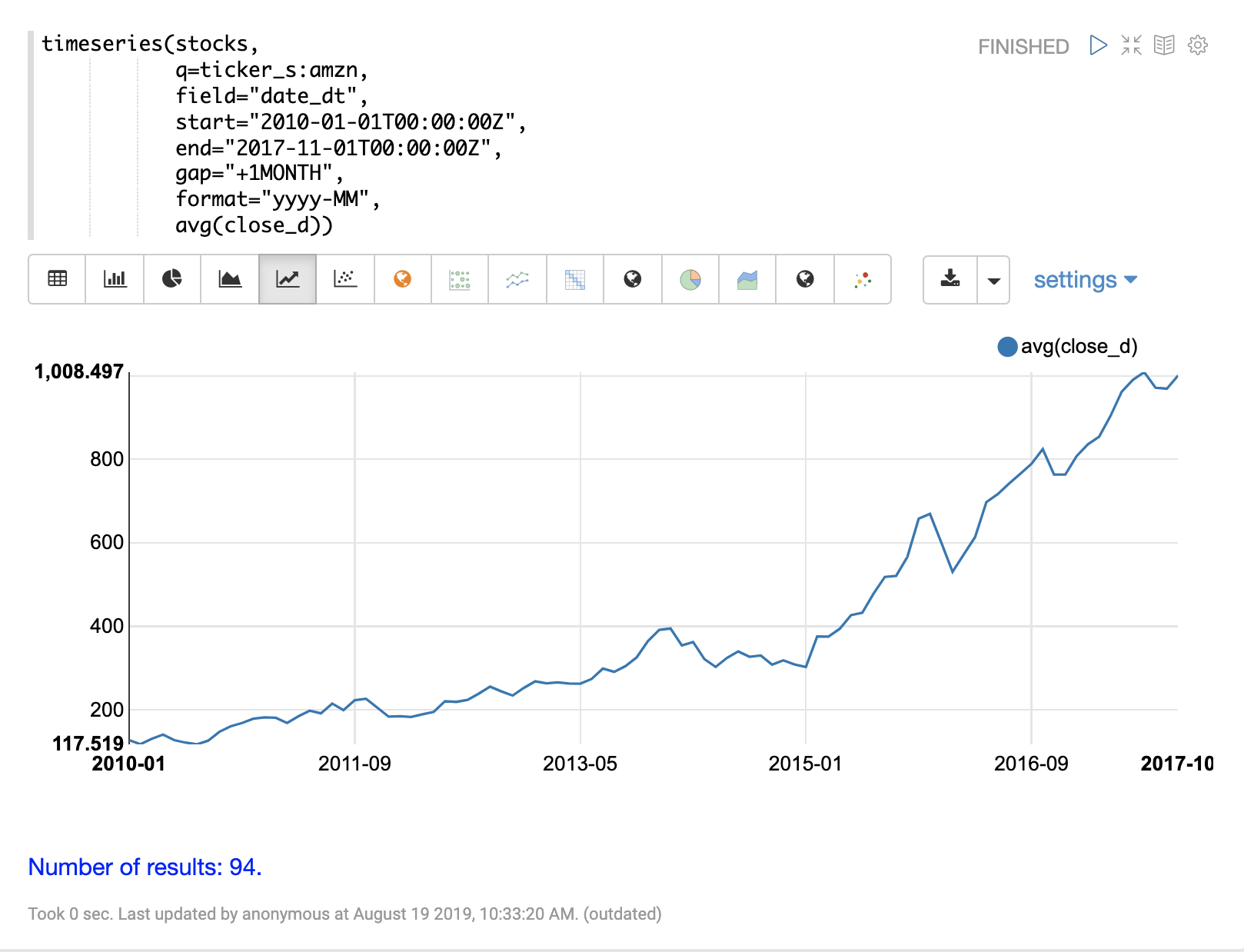
下面的示例对每日股票价格数据集合执行月度时间序列聚合。在此示例中,计算特定日期范围内股票代码为 AMZN 的平均每月收盘价。
timeseries(stocks,
q=ticker_s:amzn,
field="date_dt",
start="2010-01-01T00:00:00Z",
end="2017-11-01T00:00:00Z",
gap="+1MONTH",
format="YYYY-MM",
avg(close_d))当此表达式发送到 /stream 处理程序时,它会响应:
{
"result-set": {
"docs": [
{
"date_dt": "2010-01",
"avg(close_d)": 127.42315789473685
},
{
"date_dt": "2010-02",
"avg(close_d)": 118.02105263157895
},
{
"date_dt": "2010-03",
"avg(close_d)": 130.89739130434782
},
{
"date_dt": "2010-04",
"avg(close_d)": 141.07
},
{
"date_dt": "2010-05",
"avg(close_d)": 127.606
},
{
"date_dt": "2010-06",
"avg(close_d)": 121.66681818181816
},
{
"date_dt": "2010-07",
"avg(close_d)": 117.5190476190476
}
]}}使用 Zeppelin-Solr,可以使用折线图可视化此时间序列。
向量化时间序列
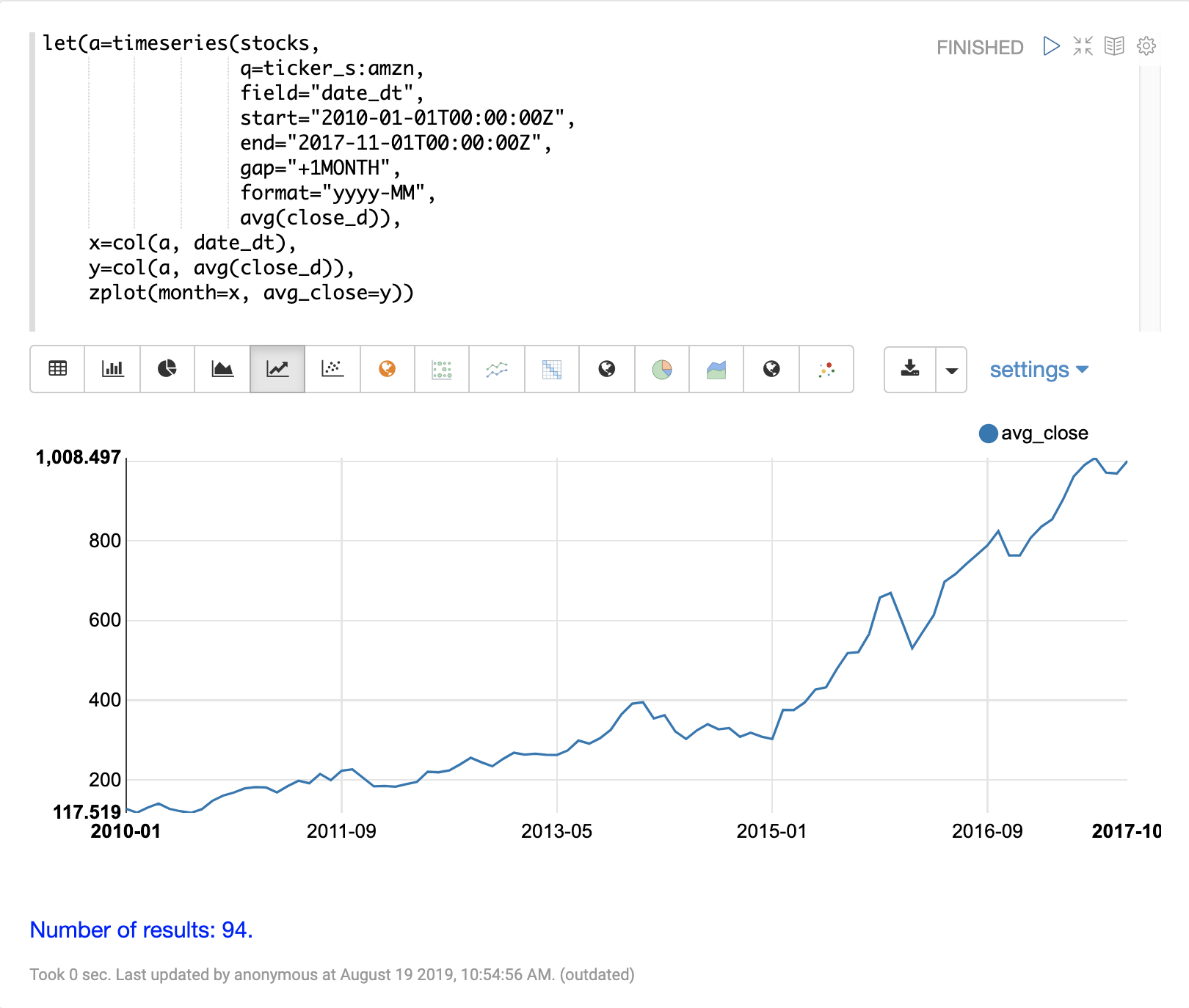
在平滑或建模时间序列之前,需要对数据进行向量化。可以使用 col 函数将数据列从元组列表复制到数组中。
下面的表达式演示了 date_dt 和 avg(close_d) 字段的向量化。然后使用 zplot 函数在 x 轴上绘制月份,在 y 轴上绘制平均收盘价。
平滑
时间序列平滑通常用于消除时间序列中的噪声,并帮助发现潜在的趋势。数学表达式库有三种滑动窗口方法用于时间序列平滑。这些方法使用来自数据滑动窗口的汇总值来计算一组新的平滑数据点。
这三个滑动窗口函数是滞后指标,这意味着它们在趋势影响滑动窗口的汇总值之前不会开始向趋势方向移动。由于这种滞后质量,这些平滑函数通常用于确认趋势的方向。
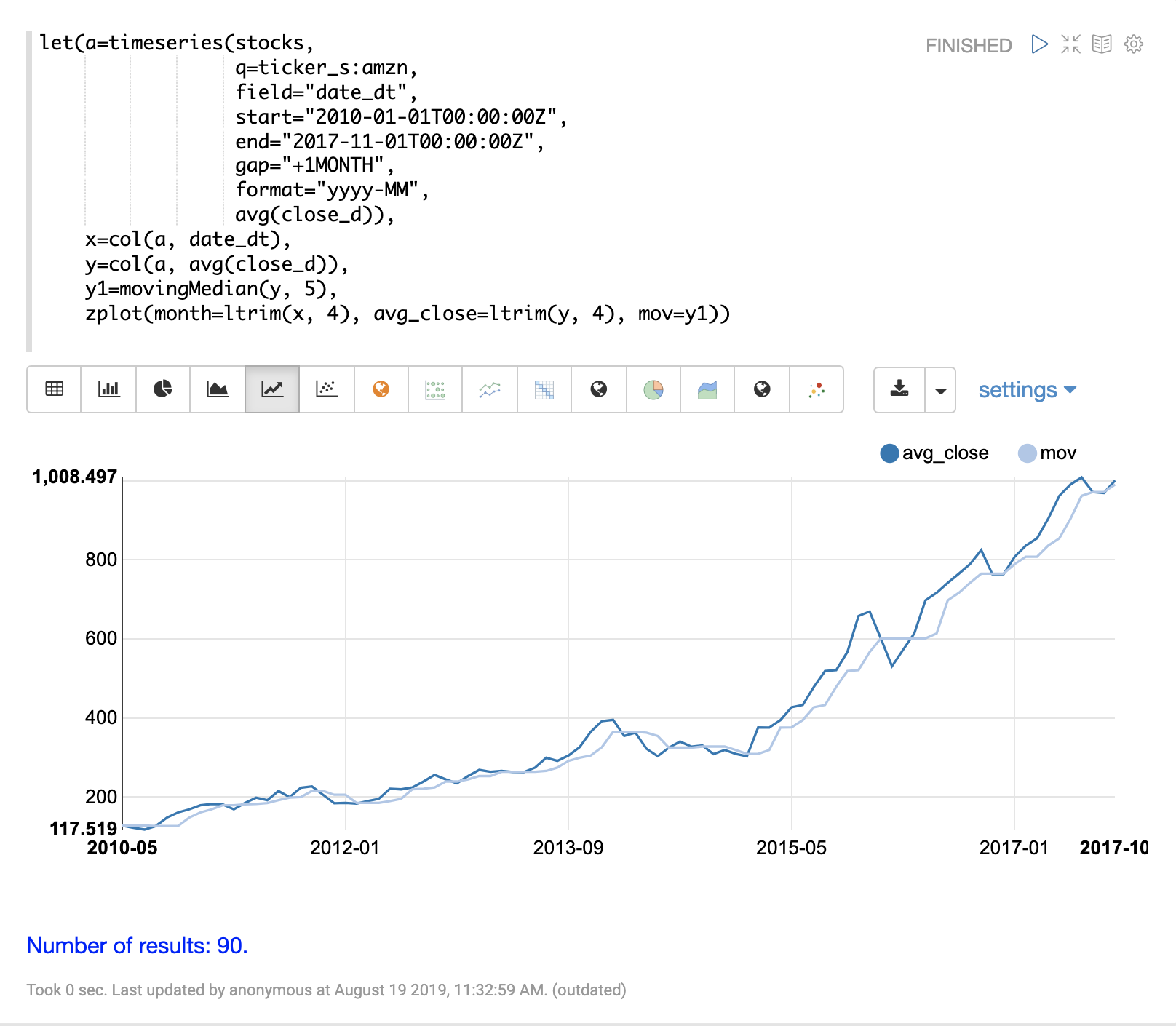
移动平均
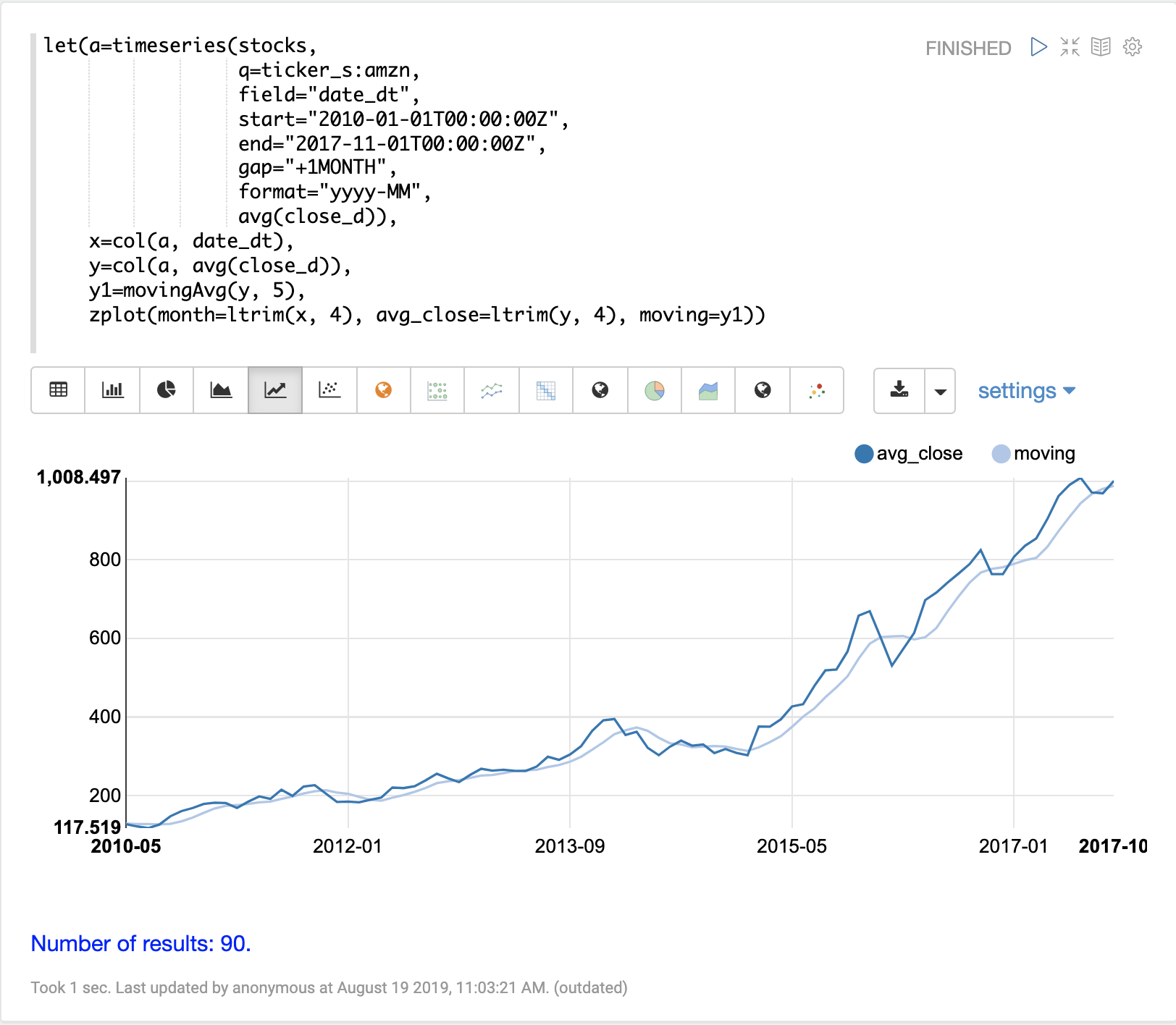
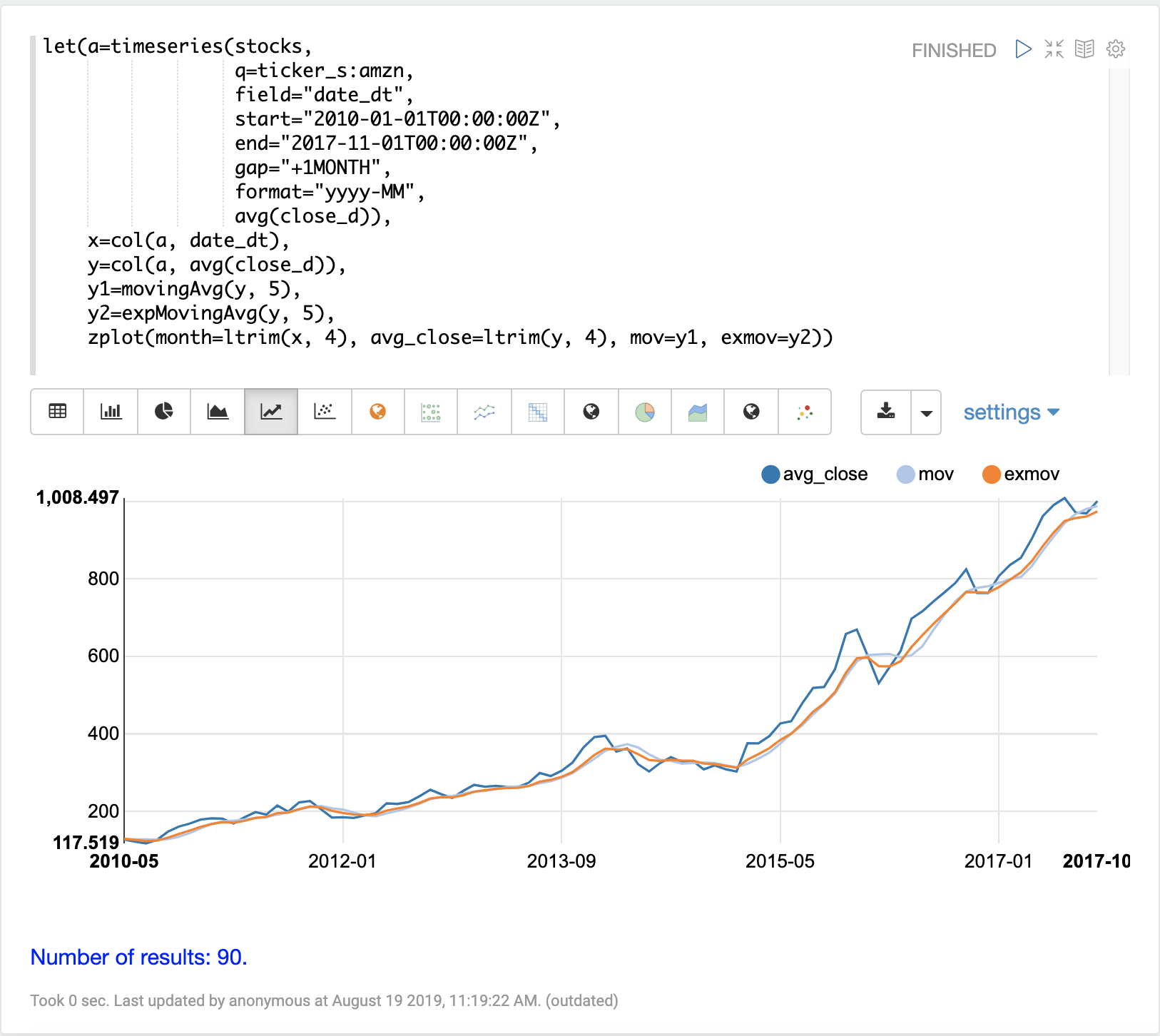
movingAvg 函数计算数据滑动窗口上的简单移动平均值。下面的示例生成一个时间序列,向量化 avg(close_d) 字段,并计算窗口大小为 5 的移动平均值。
移动平均函数返回一个长度比原始向量短的数组。这是因为仅当有完整的数据窗口可用于计算平均值时才会生成结果。对于大小为 5 的窗口,移动平均值将在第 5 个值处开始生成结果。结果中不包括先前的值。
然后使用 zplot 函数在 x 轴上绘制月份,在 y 轴上绘制平均收盘价和移动平均值。请注意,ltrim 函数用于从 x 轴和平均收盘价中修剪前 4 个值。这样做是为了对齐三个数组,使它们从第 5 个值开始。
差分
差分可以通过去除序列的趋势或季节性来使时间序列平稳。
一阶差分
差分中使用的技术是使用值之间的差异而不是原始值。一阶差分取一个值与紧随其后的值之间的差值。一阶差分通常用于消除时间序列的趋势。
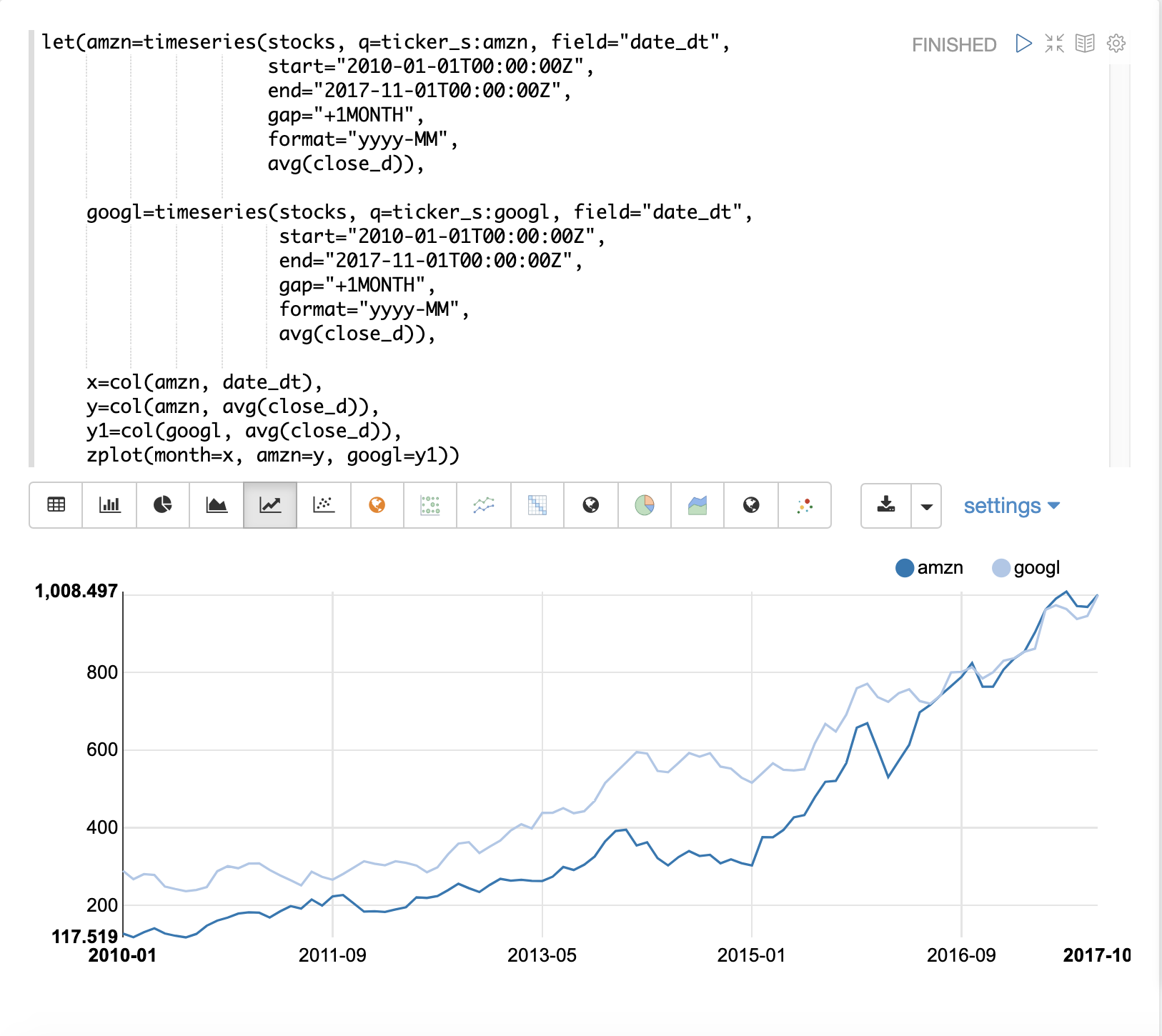
下面的示例使用一阶差分使两个时间序列平稳,以便在没有趋势的情况下进行比较。
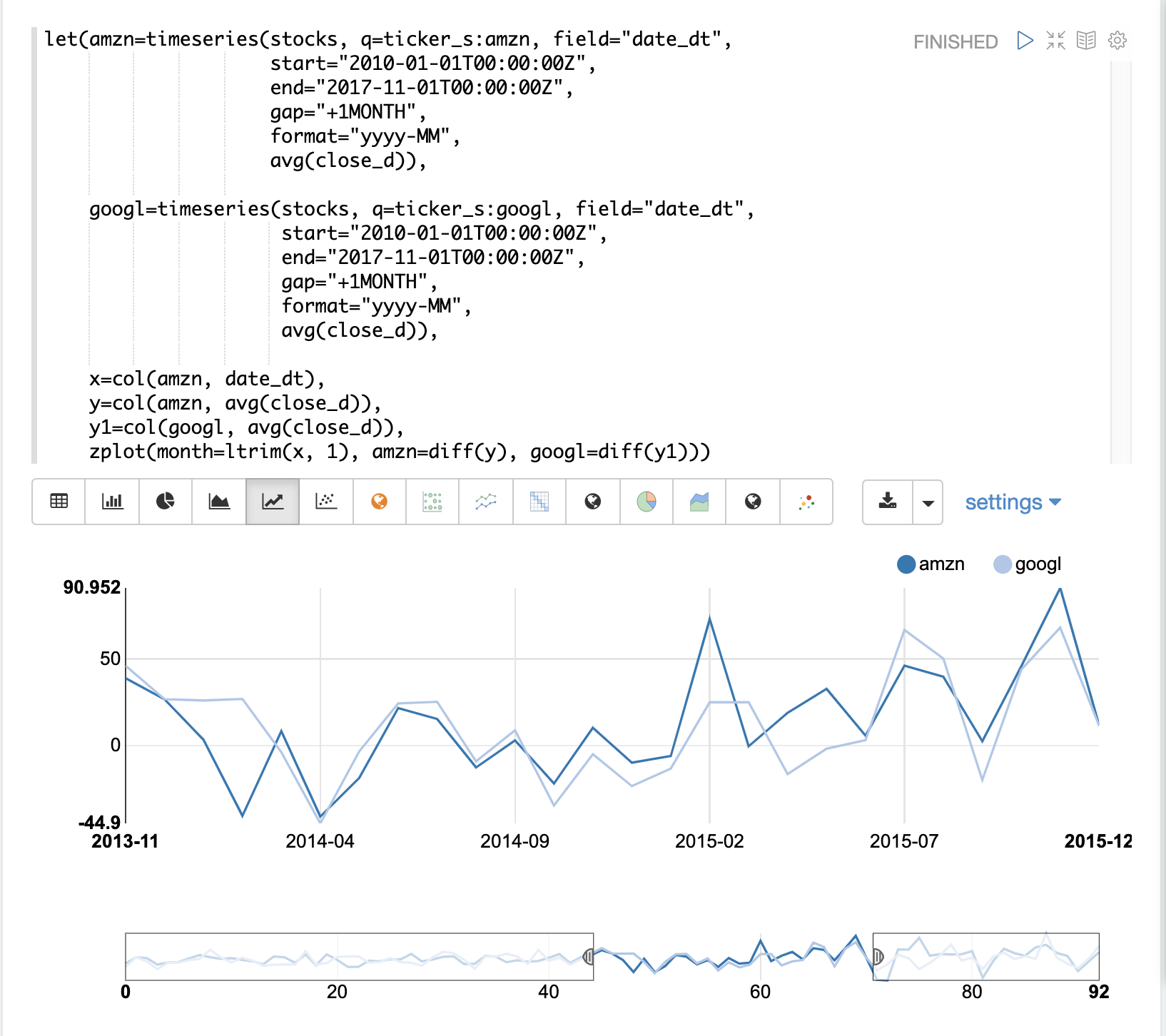
在这个例子中,我们将比较两只股票的月平均收盘价:亚马逊和谷歌。下图绘制了应用差分之前的两个时间序列。
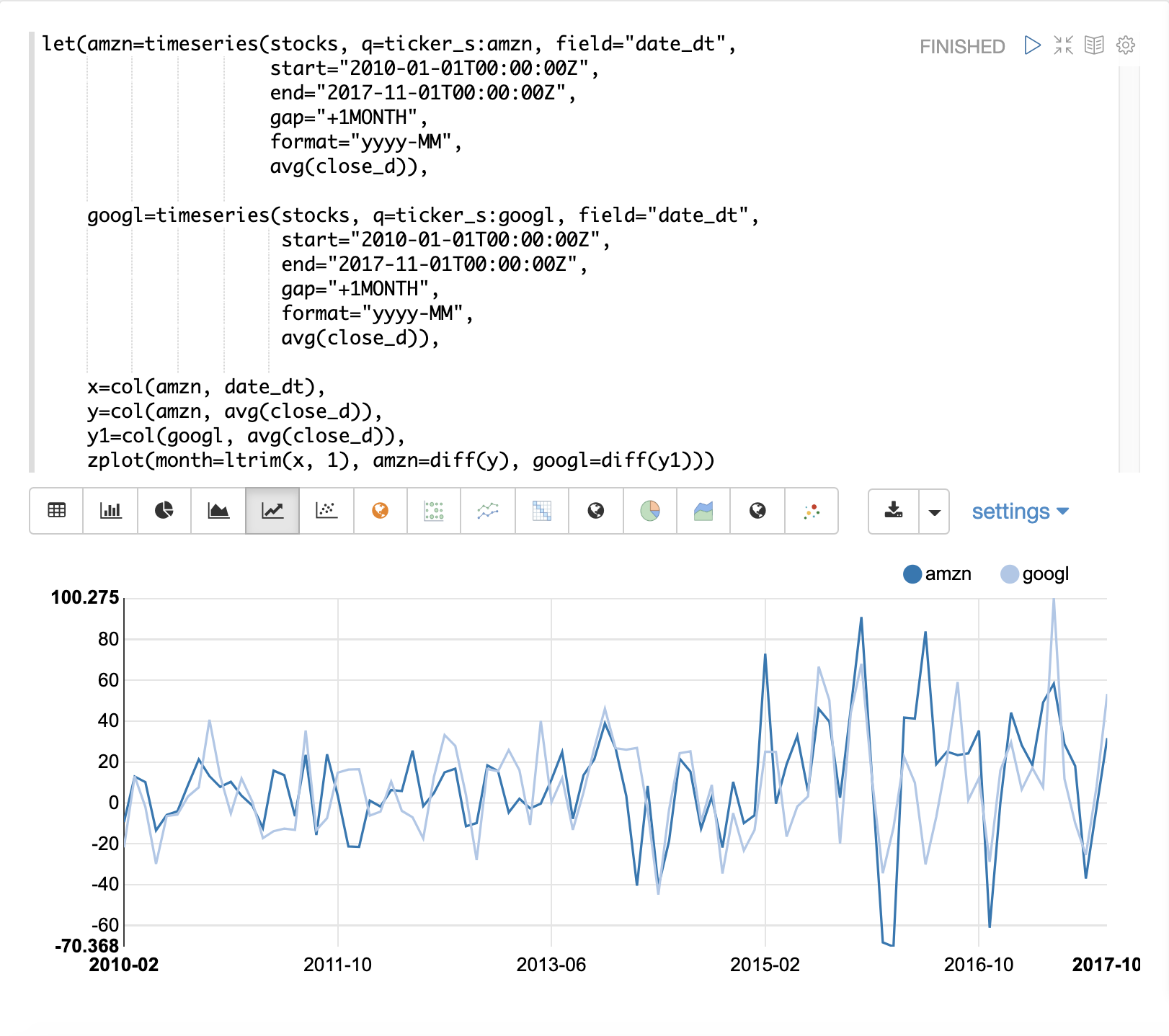
在下一个示例中,将 diff 函数应用于 zplot 函数内的两个时间序列。diff 可以在 zplot 函数内部应用,也可以像 let 函数内部的任何其他函数一样应用。
请注意,两个时间序列现在都消除了趋势,并且可以研究股票价格的每月变动,而不受趋势的影响。
在下一个示例中,使用时间序列可视化的 zoom 函数来放大到特定范围的月份。这允许更仔细地检查数据。通过更仔细地检查数据,似乎两只股票的月度走势之间存在一些相关性。
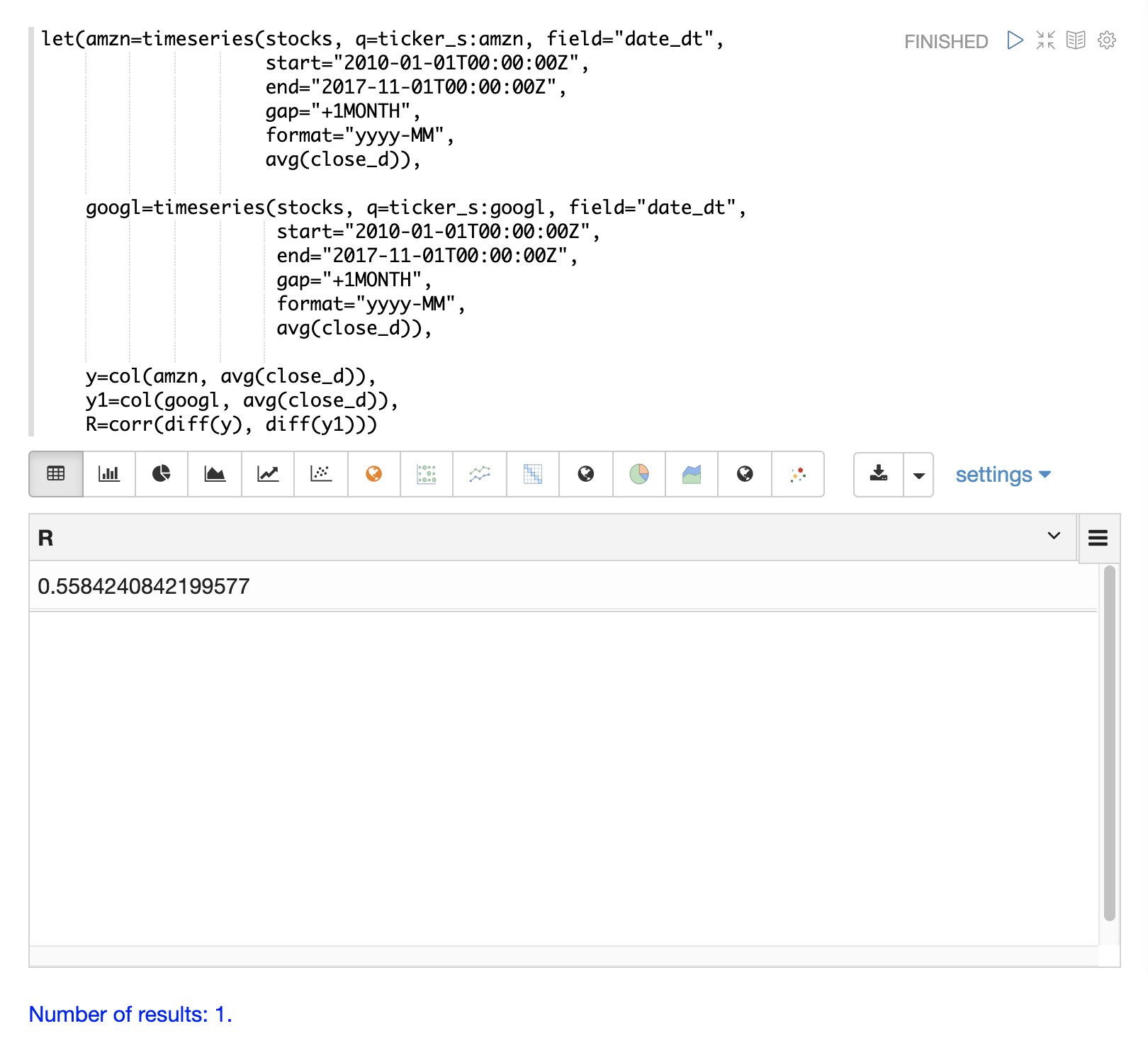
在最后一个示例中,差分的时间序列与 corr 函数相关联。
异常检测
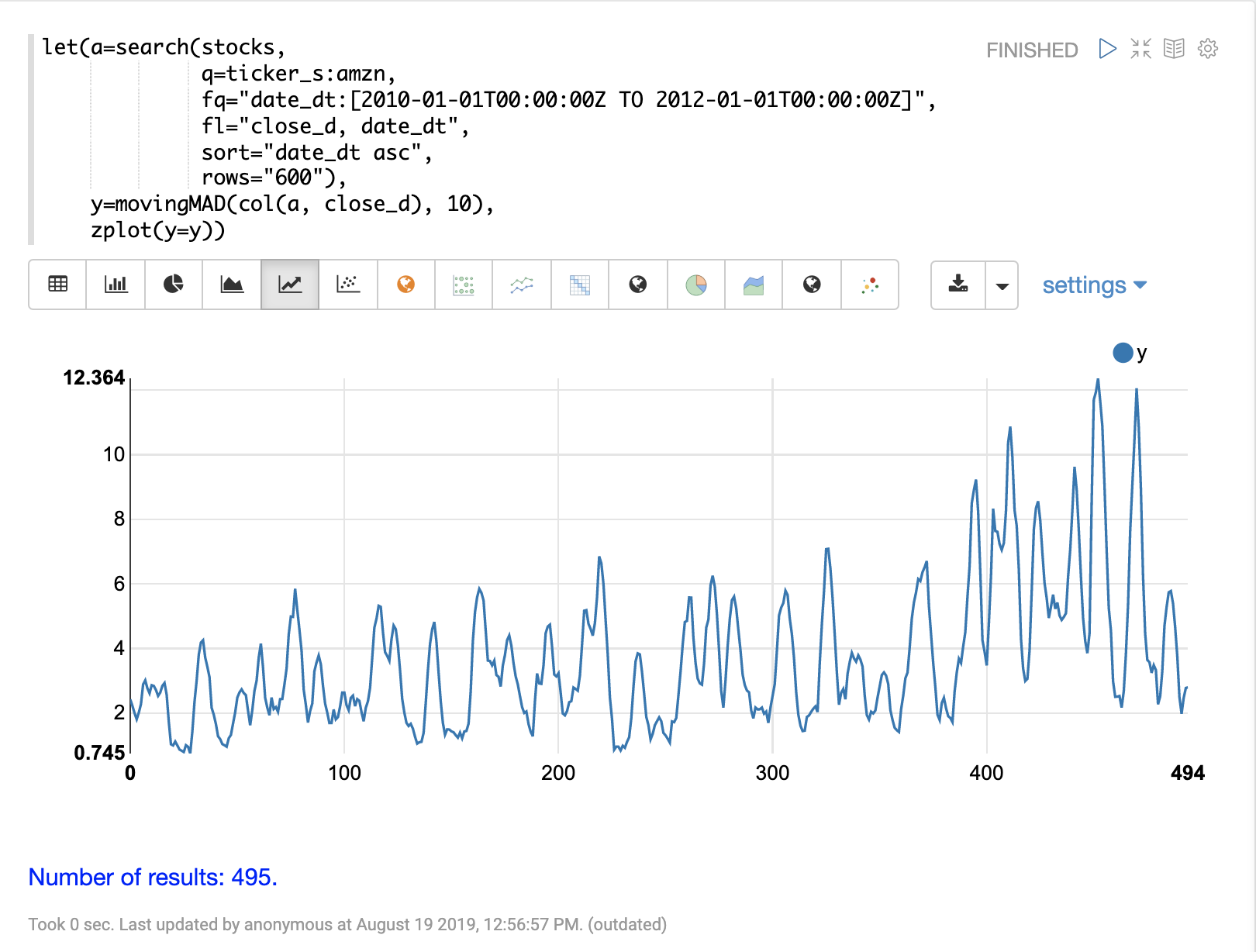
movingMAD (移动平均绝对偏差) 函数可用于通过测量滑动窗口内的离散度(偏离平均值) 来显示时间序列中的异常。
movingMAD 函数的运行方式与移动平均线类似,不同之处在于它测量窗口内的平均绝对偏差而不是平均值。通过寻找异常高或低的离散度,我们可以在时间序列中找到异常。
在此示例中,我们将使用亚马逊两年来的每日股票价格。每日股票数据将提供更大的数据集进行研究。
在下面的示例中,使用 search 表达式返回代码为 AMZN 的股票两年来的每日收盘价。
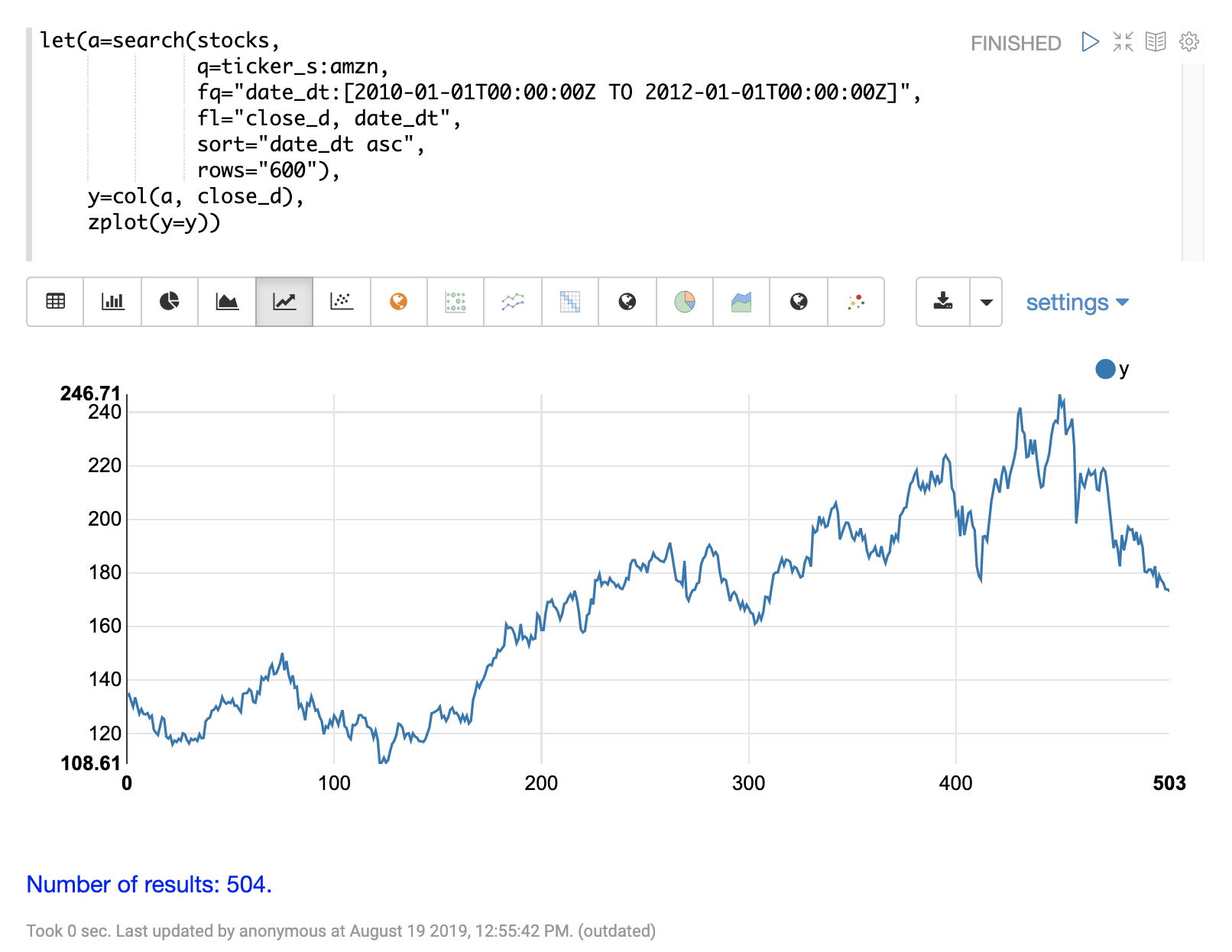
下一步是将 movingMAD 函数应用于数据,以计算 10 天窗口内的移动平均绝对偏差。下面的示例显示了如何应用和可视化该函数。
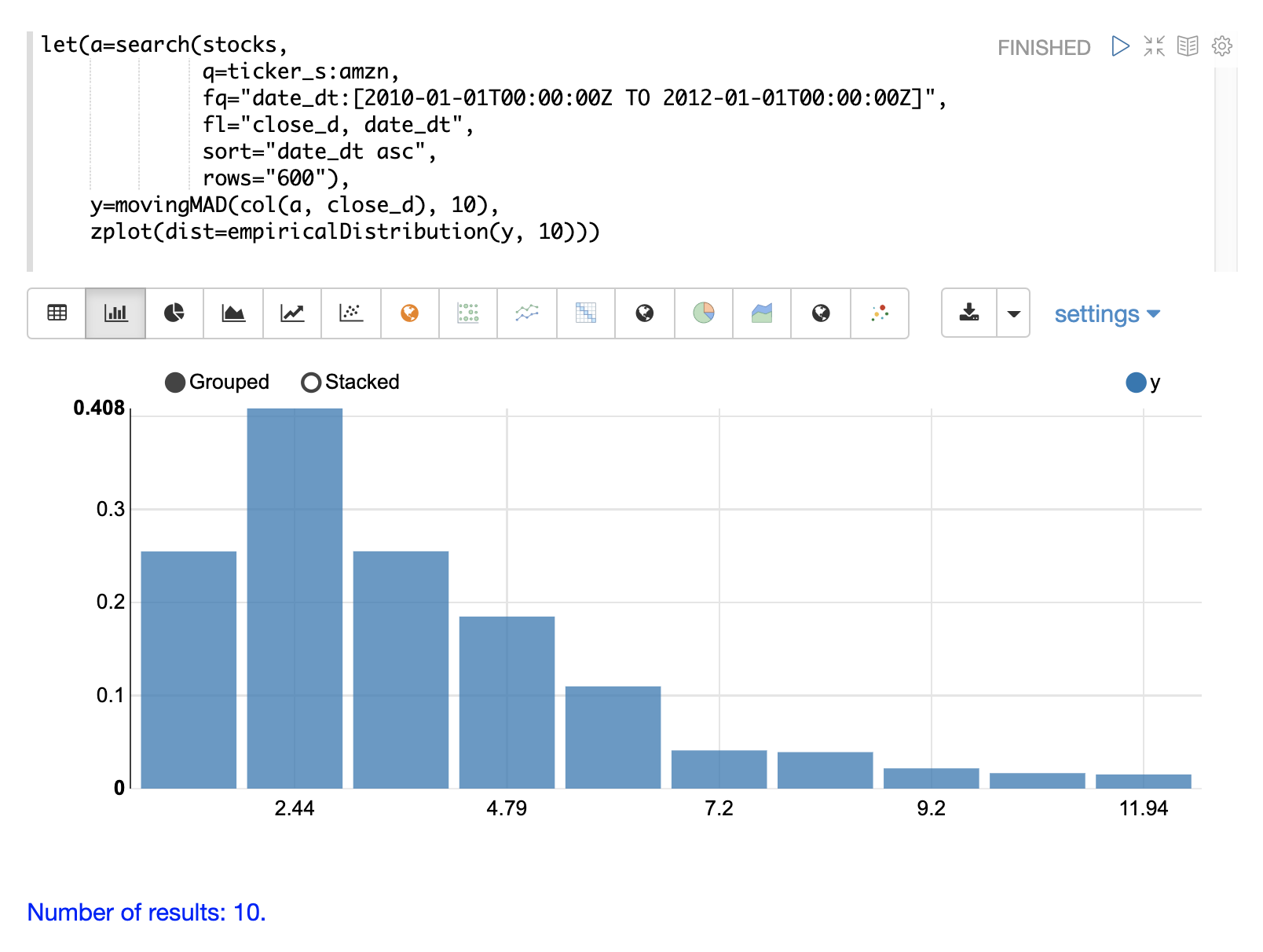
计算移动 MAD 后,我们可以使用 empiricalDistribution 函数可视化离散度的分布。下面的示例绘制了具有 10 个 bin 的经验分布,创建了时间序列离散度的 10 个 bin 直方图。
此可视化显示,大多数平均绝对偏差介于 0 和 9.2 之间,最终 bin 的平均值为 11.94。
最后一步是使用 outliers 函数检测序列中的异常值。outliers 函数使用概率分布来查找数值向量中的异常值。outliers 函数接受四个参数
-
概率分布
-
数值向量
-
低概率阈值
-
高概率阈值
-
数值向量从中选择的结果列表
outliers 函数迭代数值向量并使用概率分布来计算每个值的累积概率。如果累积概率低于低概率阈值或高于高阈值,则它将该值视为异常值。当 outliers 函数遇到异常值时,它将从第五个参数提供的结果列表中返回相应的结果。它还包括累积概率和异常值的值。
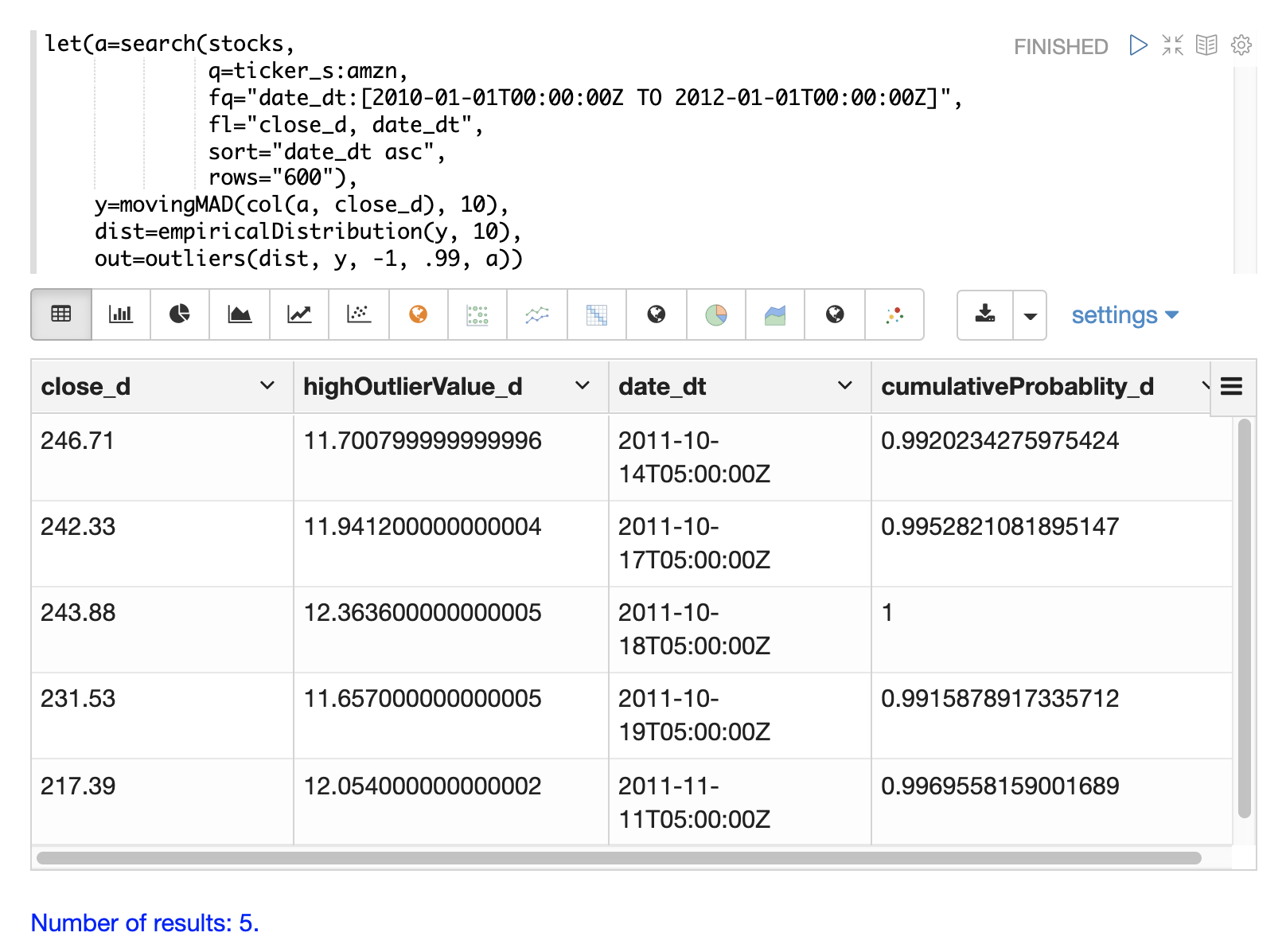
下面的示例显示了应用于亚马逊股票价格数据集的 outliers 函数。移动平均绝对偏差的经验分布是第一个参数。包含移动平均绝对偏差的向量是第二个参数。-1 是低概率阈值,.99 是高概率阈值。-1 表示不考虑低异常值。最后一个参数是包含 close_d 和 date_dt 字段的原始结果集。
outliers 函数的输出包含检测到异常值的结果。在这种情况下,检测到 5 个高于 .99 概率阈值的结果。
建模
Solr 中支持的数学表达式包含许多可用于建模时间序列的函数。这些函数包括线性回归、多项式和调和曲线拟合、局部加权回归和 KNN 回归。
这些函数中的每一个都可以对时间序列进行建模,并可用于插值(预测数据集中的值),其中一些函数可用于外推(预测超出数据集的值)。
各种回归函数在用户指南的线性回归、曲线拟合和机器学习部分中进行了详细介绍。
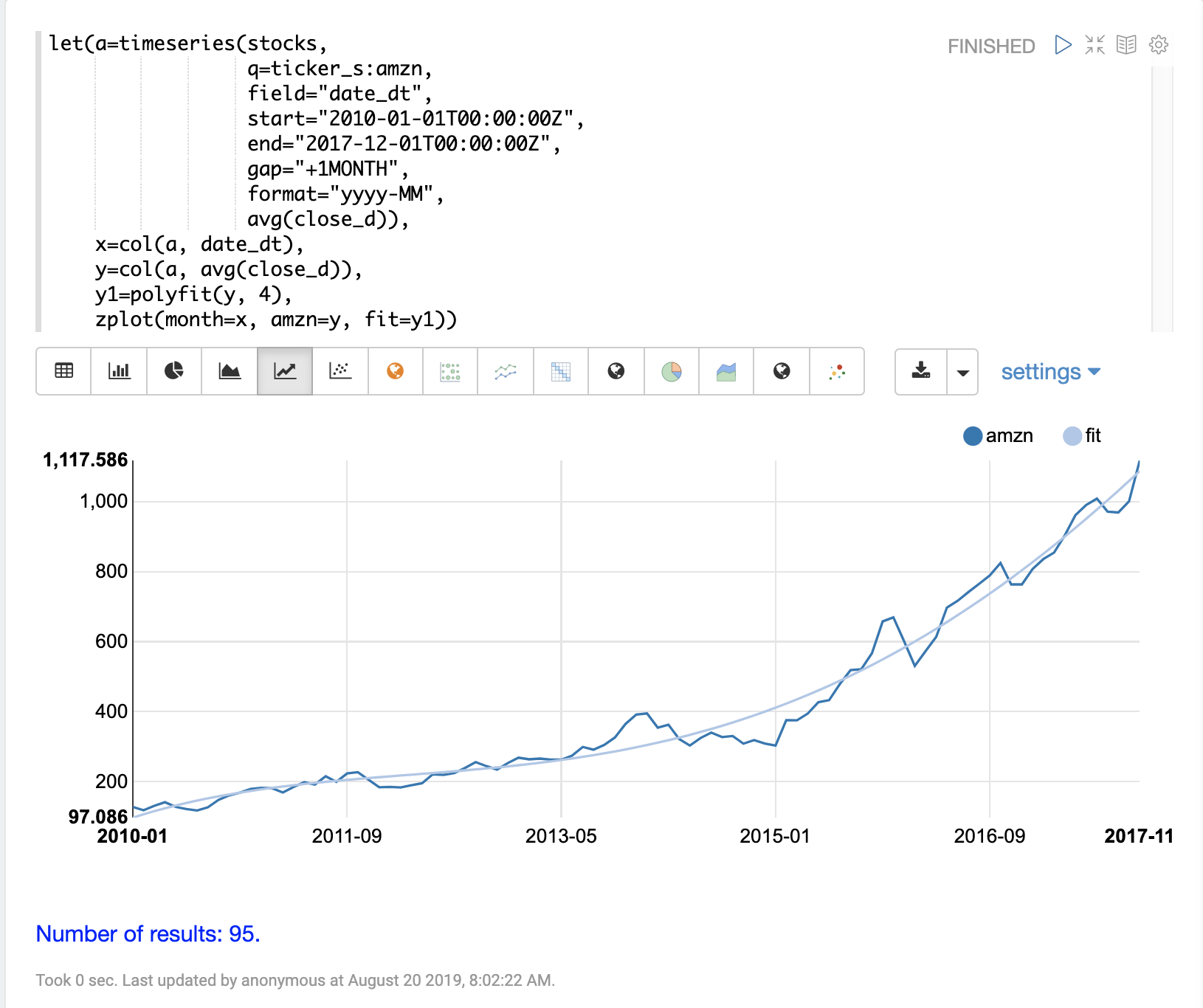
下面的示例使用 polyfit 函数 (多项式回归) 将非线性模型拟合到时间序列。所使用的数据集是亚马逊八年来的月平均收盘价。
在本示例中,polyfit 函数使用 4 次多项式返回 y 轴的拟合模型,y 轴是月平均收盘价。多项式的次数决定模型中曲线的数量。拟合模型设置为变量 y1。然后,使用 zplot 将拟合模型与原始 y 值一起直接绘制。
可视化显示了通过平均收盘价数据拟合的平滑线。
预测
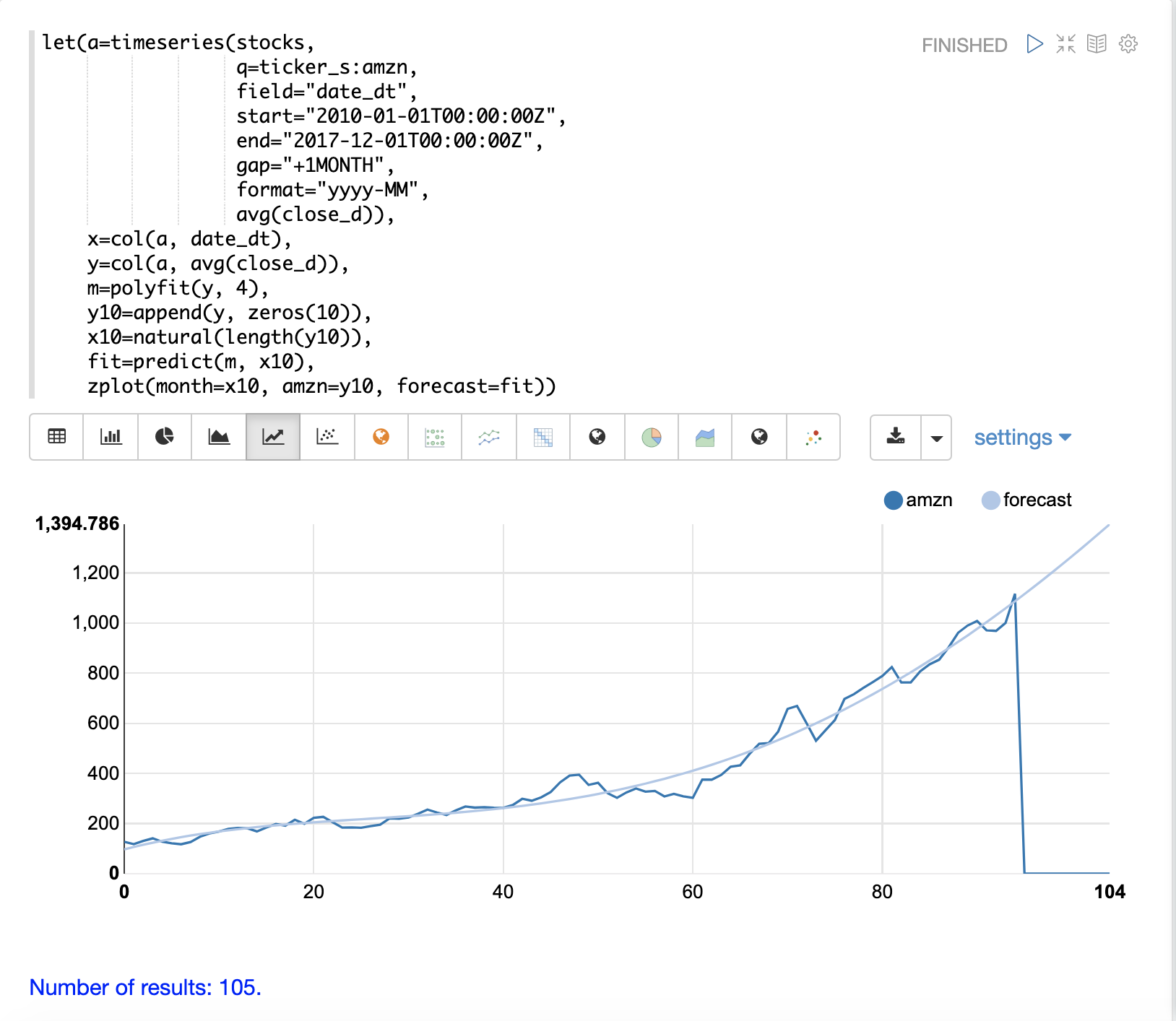
polyfit 函数还可用于外推时间序列以预测未来的股票价格。下面的示例演示了 10 个月的预测。
在示例中,polyfit 函数将模型拟合到 y 轴,并将模型设置为变量 m。然后,为了创建预测,将 10 个零附加到 y 轴,以创建一个名为 y10 的新向量。然后,使用 natural 函数创建新的 x 轴,该函数返回一个从 0 到 y10 长度的整数序列。新的 x 轴存储在变量 x10 中。
predict 函数使用拟合模型来预测存储在变量 x10 中的新 x 轴的值。
然后使用 zplot 函数在 x 轴上绘制 x10 向量,在 y 轴上绘制 y10 向量和外推模型。请注意,y10 向量在观测数据结束时降至零,但预测会沿着模型的拟合曲线继续。