图
用户指南的这一部分涵盖了图表达式背后的语法和理论。 针对两个关键的图用例提供了示例:二分图推荐器和使用时间图查询的事件相关性。
图
Solr 中索引的日志记录和其他数据之间存在连接,这些连接可以被视为分布式图。 图表达式提供了一种机制来识别图中的根节点并遍历它们的连接。 图遍历的总体目标是实现特定的子图并执行链接分析以了解节点之间的连接。
在下面的几个部分中,我们将回顾 Solr 图表达式背后的图论。
子图
子图是较大图的节点和连接的较小子集。 图表达式允许您从存储在分布式索引中的较大图中灵活地定义和实现子图。
子图发挥两个重要作用
-
它们为链接分析提供局部上下文。 子图的设计定义了链接分析的含义。
-
它们提供了一个可以与背景索引进行比较的前景图,用于异常检测目的。
二分图子图
图表达式可用于实现二分图子图。 二分图是一种节点分为两个不同类别的图。 然后可以分析这两个类别之间的链接以研究它们之间的关系。 二分图通常在协同过滤推荐系统的上下文中讨论。
购物篮和产品之间的二分图是一个有用的示例。 通过购物篮和产品之间的链接分析,我们可以确定哪些产品最常在同一购物篮中购买。
在下面的示例中,有一个名为 baskets 的 Solr 集合,其中包含三个字段
id:唯一 ID
basket_s:购物篮 ID
product_s:产品
集合中的每条记录代表一个购物篮中的产品。 同一个购物篮中的所有产品共享相同的购物篮 ID。
让我们考虑一个简单的示例,其中我们要查找通常与黄油一起销售的产品。 为了做到这一点,我们可以创建一个包含黄油的购物篮的二分图子图。 我们不会在图中包含黄油本身,因为它无助于找到黄油的补充产品。
下面是以矩阵形式表示的二分图子图的示例
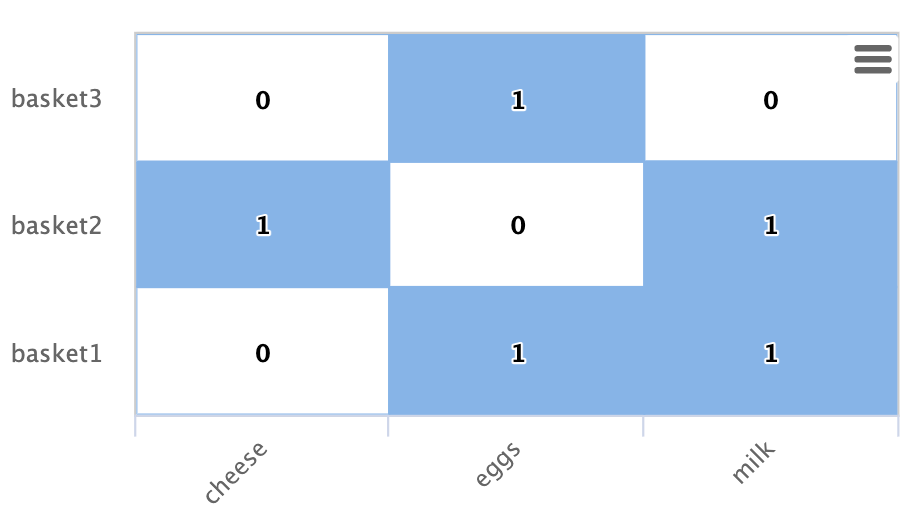
在此示例中,有三个购物篮由行显示:basket1、basket2、basket3。
还有三个产品由列显示:奶酪、鸡蛋、牛奶。
每个单元格都有 1 或 0,表示产品是否在购物篮中。
让我们看看 Solr 图表达式如何实现此二分图子图
nodes 函数用于实现较大图中的子图。 以下是示例 nodes 函数,该函数实现上面矩阵中显示的二分图。
nodes(baskets,
random(baskets, q="product_s:butter", fl="basket_s", rows="3"),
walk="basket_s->basket_s",
fq="-product_s:butter",
gather="product_s",
trackTraversal="true")让我们从 random 函数开始分解这个示例
random(baskets, q="product_s:butter", fl="basket_s", rows="3")random 函数正在使用查询 product_s:butter 搜索 baskets 集合,并返回 3 个随机样本。 每个样本都包含 basket_s 字段,即购物篮 id。 随机样本返回的三个购物篮 id 是图查询的根节点。
nodes 函数是图查询。 nodes 函数对 random 函数返回的三个根节点进行操作。 它通过在索引中针对 basket_s 字段搜索根节点的 basket_s 字段来“遍历”图。 这会找到根购物篮的所有产品记录。 然后,它将从遍历中找到的记录中“收集” product_s 字段。 应用过滤器,以便不会返回 product_s 字段中包含黄油的记录。
trackTraversal 标志告诉节点表达式跟踪根购物篮和产品之间的链接。
节点集
节点函数的输出是一个节点集,表示由节点函数指定的子图。该节点集包含在图遍历期间收集的一组唯一节点。结果中的 node 属性是收集到的节点的值。在购物篮示例中,product_s 字段在节点属性中,因为这是在节点表达式中指定要收集的内容。
购物篮图表达式的输出如下:
{
"result-set": {
"docs": [
{
"node": "eggs",
"collection": "baskets",
"field": "product_s",
"ancestors": [
"basket1",
"basket3"
],
"level": 1
},
{
"node": "cheese",
"collection": "baskets",
"field": "product_s",
"ancestors": [
"basket2"
],
"level": 1
},
{
"node": "milk",
"collection": "baskets",
"field": "product_s",
"ancestors": [
"basket1",
"basket2"
],
"level": 1
},
{
"EOF": true,
"RESPONSE_TIME": 12
}
]
}
}结果中的 ancestors 属性包含一个唯一的、按字母顺序排序的集合,其中包含子图中节点的所有入站链接。在这种情况下,它显示了链接到每个产品的购物篮。只有当在节点表达式中启用 trackTraversal 标志时,才会跟踪祖先链接。
链接分析和度中心性
链接分析通常用于确定节点中心性。在分析中心性时,目标是根据每个节点在子图中的连接程度为其分配权重。节点中心性有不同的类型。图表达式可以非常有效地计算入度中心性(入度)。
入度中心性是通过计算每个节点的入站链接数来计算的。为简单起见,本文档有时将入度简称为度。
回到购物篮示例
我们可以通过对列求和来计算图中产品的度
cheese: 1
eggs: 2
milk: 2从度的计算中,我们知道鸡蛋和牛奶在含有黄油的购物篮中出现的频率比奶酪高。
节点函数可以通过添加 count(*) 聚合来计算度中心性,如下所示
nodes(baskets,
random(baskets, q="product_s:butter", fl="basket_s", rows="3"),
walk="basket_s->basket_s",
fq="-product_s:butter",
gather="product_s",
trackTraversal="true",
count(*))此图表达式的输出如下:
{
"result-set": {
"docs": [
{
"node": "eggs",
"count(*)": 2,
"collection": "baskets",
"field": "product_s",
"ancestors": [
"basket1",
"basket3"
],
"level": 1
},
{
"node": "cheese",
"count(*)": 1,
"collection": "baskets",
"field": "product_s",
"ancestors": [
"basket2"
],
"level": 1
},
{
"node": "milk",
"count(*)": 2,
"collection": "baskets",
"field": "product_s",
"ancestors": [
"basket1",
"basket2"
],
"level": 1
},
{
"EOF": true,
"RESPONSE_TIME": 17
}
]
}
}count(*) 聚合计算“收集”的节点,在本例中为 product_s 字段中的值。请注意,count(*) 的结果与祖先的数量相同。情况总是如此,因为节点函数在计数收集的节点之前首先删除重复的边。因此,count(*) 聚合始终计算收集节点的入度中心性。
点积
入度与二分图推荐器和点积之间存在直接关系。一旦我们包含一个用于黄油的列,这种关系可以在我们的工作示例中清楚地看到
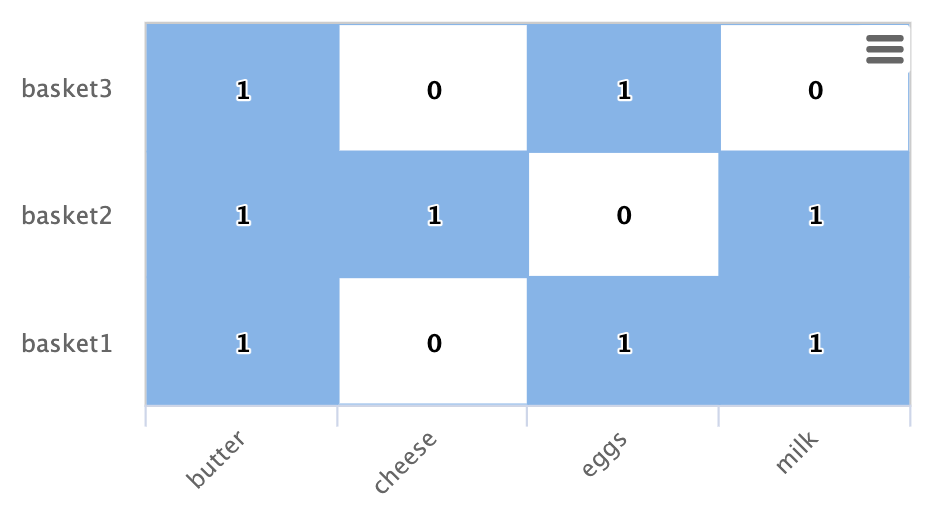
如果我们计算黄油列和其他产品列之间的点积,您会发现点积在每种情况下都等于入度。这告诉我们,使用最大内积相似度的最近邻搜索将选择入度最高的列。
限制购物篮出度
通过限制购物篮的出度可以使推荐更有效。出度是图中节点的出站链接数。在购物篮示例中,购物篮的出站链接链接到产品。因此,限制出度将限制购物篮的大小。
为什么限制购物篮的大小会使推荐更有效?要回答这个问题,有助于将每个购物篮视为投票给与黄油搭配的产品。在有两个候选人的选举中,如果您投票给两个候选人,则投票将相互抵消,不起作用。但是,如果您只投票给一个候选人,则您的投票将影响结果。相同的原理适用于推荐。当一个购物篮投票给更多产品时,它会削弱其对任何一个产品的推荐强度。仅包含黄油和一个其他物品的购物篮会更强烈地推荐该物品。
maxDocFreq 参数可用于限制图“遍历”,使其仅包括在索引中出现一定次数的购物篮。由于索引中每次出现购物篮 ID 都是指向产品的链接,因此限制购物篮 ID 的文档频率将限制购物篮的出度。maxDocFreq 参数是按分片应用的。如果只有一个分片或文档按购物篮 ID 共址,则 maxDocFreq 将是精确计数。否则,它将返回最大大小为 numShards * maxDocFreq 的购物篮。
下面的示例显示了应用于 nodes 表达式的 maxDocFreq 参数。
nodes(baskets,
random(baskets, q="product_s:butter", fl="basket_s", rows="3"),
walk="basket_s->basket_s",
maxDocFreq="5",
fq="-product_s:butter",
gather="product_s",
trackTraversal="true",
count(*))节点评分
节点的度描述了子图中链接到它的节点数量。但这并不能告诉我们该节点是否对该子图特别重要,或者它只是整个图中非常频繁的节点。在子图中频繁出现但在整个图中不频繁出现的节点可以被认为与子图更相关。
搜索索引包含有关每个节点在整个索引中出现的频率的信息。使用类似于 tf-idf 文档评分的技术,图表达式可以将节点的度与其在索引中的逆文档频率相结合,以确定相关性分数。
scoreNodes 函数对节点进行评分。下面是将 scoreNodes 函数应用于购物篮节点集的示例。
scoreNodes(nodes(baskets,
random(baskets, q="product_s:butter", fl="basket_s", rows="3"),
walk="basket_s->basket_s",
fq="-product_s:butter",
gather="product_s",
trackTraversal="true",
count(*)))输出现在包含 nodeScore 属性。在下面的输出中,请注意,即使 鸡蛋 与 牛奶 具有相同的 count(*),但 鸡蛋 的 nodeScore 高于 牛奶。这是因为牛奶在整个索引中出现的频率高于鸡蛋。nodeScore 函数添加的 docFreq 属性显示了索引中的文档频率。由于 docFreq 较低,鸡蛋被认为与此子图更相关,是与黄油搭配的更好推荐。
{
"result-set": {
"docs": [
{
"node": "eggs",
"nodeScore": 3.8930247,
"field": "product_s",
"numDocs": 10,
"level": 1,
"count(*)": 2,
"collection": "baskets",
"ancestors": [
"basket1",
"basket3"
],
"docFreq": 2
},
{
"node": "milk",
"nodeScore": 3.0281217,
"field": "product_s",
"numDocs": 10,
"level": 1,
"count(*)": 2,
"collection": "baskets",
"ancestors": [
"basket1",
"basket2"
],
"docFreq": 4
},
{
"node": "cheese",
"nodeScore": 2.7047482,
"field": "product_s",
"numDocs": 10,
"level": 1,
"count(*)": 1,
"collection": "baskets",
"ancestors": [
"basket2"
],
"docFreq": 1
},
{
"EOF": true,
"RESPONSE_TIME": 26
}
]
}
}时序图表达式
上面的示例为时序图查询奠定了基础。时序图查询允许 nodes 函数使用时间窗口遍历图,以揭示时序图中的交叉相关性。节点函数当前支持使用十秒窗口、每日窗口和工作日窗口的图遍历。
十秒窗口对于日志分析中的事件关联和根本原因分析非常有用。每日和工作日窗口对于关联几天后发生的事件非常有用。
为了支持时序图查询,必须在索引时将截断的 ISO 8601 格式的时间戳作为字符串字段添加到日志记录中。为了支持十秒时间窗口,应将十秒截断的时间戳索引到字符串字段中,如下所示:2021-02-10T20:51:30Z 。为了支持每日和每周时间窗口,应将每日截断的时间戳索引到字符串字段中,如下所示:2021-02-10T00:00:00Z。
此处 描述的 Solr 日志的 Solr 索引工具已经添加了十秒截断时间戳。因此,使用 Solr 分析 Solr 日志的人可以免费获得时序图表达式。
根事件
一旦将十秒窗口与日志记录一起索引,我们就可以设计一个查询,创建一组根事件。我们可以通过一个使用 Solr 日志记录的示例来说明这一点。
在此示例中,我们将执行 Streaming Expression facet 聚合,该聚合查找平均查询时间最高的 10 个十秒窗口。这些时间窗口可用于表示时序图查询中的慢查询事件。
这是 facet 函数
facet(solr_logs, q="+type_s:query +distrib_s:false", buckets="time_ten_second_s", avg(qtime_i))下面是结果的片段,其中包含平均查询时间最高的 25 个窗口
{
"result-set": {
"docs": [
{
"avg(qtime_i)": 105961.38461538461,
"time_ten_second_s": "2020-08-25T21:05:00Z"
},
{
"avg(qtime_i)": 93150.16666666667,
"time_ten_second_s": "2020-08-25T21:04:50Z"
},
{
"avg(qtime_i)": 87742,
"time_ten_second_s": "2020-08-25T21:04:40Z"
},
{
"avg(qtime_i)": 72081.71929824562,
"time_ten_second_s": "2020-08-25T21:05:20Z"
},
{
"avg(qtime_i)": 62741.666666666664,
"time_ten_second_s": "2020-08-25T12:30:20Z"
},
{
"avg(qtime_i)": 56526,
"time_ten_second_s": "2020-08-25T12:41:20Z"
},
...
{
"avg(qtime_i)": 12893,
"time_ten_second_s": "2020-08-25T17:28:10Z"
},
{
"EOF": true,
"RESPONSE_TIME": 34
}
]
}
}时序二分图
一旦我们确定了一组根事件,就可以很容易地执行一个图查询,该查询创建一个在同一十秒窗口内发生的日志事件类型的二分图。对于 Solr 日志,有一个名为 type_s 的字段,它是日志事件的类型。
为了查看哪些日志事件与我们的根事件在同一十秒窗口中发生,我们可以“遍历”十秒窗口并收集 type_s 字段。
nodes(solr_logs,
facet(solr_logs,
q="+type_s:query +distrib_s:false",
buckets="time_ten_second_s",
avg(qtime_i)),
walk="time_ten_second_s->time_ten_second_s",
gather="type_s",
count(*))下面是生成的节点集
{
"result-set": {
"docs": [
{
"node": "query",
"count(*)": 10,
"collection": "solr_logs",
"field": "type_s",
"level": 1
},
{
"node": "admin",
"count(*)": 2,
"collection": "solr_logs",
"field": "type_s",
"level": 1
},
{
"node": "other",
"count(*)": 3,
"collection": "solr_logs",
"field": "type_s",
"level": 1
},
{
"node": "update",
"count(*)": 2,
"collection": "solr_logs",
"field": "type_s",
"level": 1
},
{
"node": "error",
"count(*)": 1,
"collection": "solr_logs",
"field": "type_s",
"level": 1
},
{
"EOF": true,
"RESPONSE_TIME": 50
}
]
}
}在此结果集中,node 字段包含在与根事件相同的十秒窗口内发生的日志事件的类型。请注意,事件类型包括:查询、管理、更新和错误。count(*) 显示不同日志事件类型的度中心性。
请注意,在慢查询事件的同一十秒窗口内,只有一个错误事件。
窗口参数
对于事件关联和根本原因分析,仅查找在相同十秒根事件窗口内发生的事件是不够的。需要查找在每个根事件之前的时间窗口内发生的事件。window 参数允许您在查询中指定此之前的时间窗口。窗口参数是一个整数,它指定在每个根事件窗口之前要包括在图遍历中的十秒时间窗口数。
nodes(solr_logs,
facet(solr_logs,
q="+type_s:query +distrib_s:false",
buckets="time_ten_second_s",
avg(qtime_i)),
walk="time_ten_second_s->time_ten_second_s",
gather="type_s",
window="-3",
count(*))请注意,本示例中的窗口参数为负数 (-3)。这将从事件开始回溯时间。正窗口将向前推进时间。
下面是添加窗口参数后返回的节点集。请注意,在慢查询事件之前的 3 个十秒窗口内,现在有 29 个错误事件。
{
"result-set": {
"docs": [
{
"node": "query",
"count(*)": 62,
"collection": "solr_logs",
"field": "type_s",
"level": 1
},
{
"node": "admin",
"count(*)": 41,
"collection": "solr_logs",
"field": "type_s",
"level": 1
},
{
"node": "other",
"count(*)": 48,
"collection": "solr_logs",
"field": "type_s",
"level": 1
},
{
"node": "update",
"count(*)": 11,
"collection": "solr_logs",
"field": "type_s",
"level": 1
},
{
"node": "error",
"count(*)": 29,
"collection": "solr_logs",
"field": "type_s",
"level": 1
},
{
"EOF": true,
"RESPONSE_TIME": 117
}
]
}
}度作为相关性的表示
通过对时序二分图执行链接分析,我们可以计算每个在指定时间窗口内发生的事件类型的度。我们在二分图推荐器示例中建立了入度与点积之间的直接关系。在数字信号处理领域,点积用于表示相关性。在我们的时序图查询中,我们可以将入度视为根事件与在指定时间窗口内发生的事件之间的相关性表示。
滞后参数
了解相关性中的滞后对于某些用例非常重要。在滞后相关性中,一个事件发生,在延迟之后,另一个事件发生。窗口参数不会捕获延迟,因为我们只知道事件发生在先前窗口的某个位置。
lag 参数可用于在过去指定数量的十秒窗口中开始计算窗口参数。例如,我们可以从一组根事件之前 30 秒开始,在 20 秒窗口中遍历图。通过调整滞后并重新运行查询,我们可以确定哪个滞后窗口的度最高。由此我们可以确定延迟。
节点评分和时序异常检测
节点评分的概念可以应用于时序图查询,以查找既与一组根事件相关又对根事件异常的事件。度计算建立事件之间的相关性,但它不确定该事件在整个图中是否非常常见,或者是否特定于子图。
可以应用 scoreNodes 函数,以根据度和节点项在索引中的普遍性对节点进行评分。这将确定事件是否对根事件异常。
scoreNodes(nodes(solr_logs,
facet(solr_logs,
q="+type_s:query +distrib_s:false",
buckets="time_ten_second_s",
avg(qtime_i)),
walk="time_ten_second_s->time_ten_second_s",
gather="type_s",
window="-3",
count(*)))下面是一旦应用 scoreNodes 函数后的节点集。现在我们看到得分最高的节点是错误事件。此分数很好地指示了我们开始根本原因分析的位置。
{
"result-set": {
"docs": [
{
"node": "other",
"nodeScore": 23.441727,
"field": "type_s",
"numDocs": 4513625,
"level": 1,
"count(*)": 48,
"collection": "solr_logs",
"docFreq": 99737
},
{
"node": "query",
"nodeScore": 16.957537,
"field": "type_s",
"numDocs": 4513625,
"level": 1,
"count(*)": 62,
"collection": "solr_logs",
"docFreq": 449189
},
{
"node": "admin",
"nodeScore": 22.829023,
"field": "type_s",
"numDocs": 4513625,
"level": 1,
"count(*)": 41,
"collection": "solr_logs",
"docFreq": 96698
},
{
"node": "update",
"nodeScore": 3.9480786,
"field": "type_s",
"numDocs": 4513625,
"level": 1,
"count(*)": 11,
"collection": "solr_logs",
"docFreq": 3838884
},
{
"node": "error",
"nodeScore": 26.62394,
"field": "type_s",
"numDocs": 4513625,
"level": 1,
"count(*)": 29,
"collection": "solr_logs",
"docFreq": 27622
},
{
"EOF": true,
"RESPONSE_TIME": 124
}
]
}
}日和工作日时间窗口
要切换到天或工作日时间窗口,我们必须首先在日志记录的字符串字段中索引截断为天的 ISO 8601 时间戳。 在下面的示例中,字段 time_day_s 包含截断为天的时间戳。
然后,只需在窗口参数中指定 -3DAYS 即可。 这会将默认的十秒时间窗口切换为每日窗口。
scoreNodes(nodes(solr_logs,
facet(solr_logs,
q="+type_s:query +distrib_s:false",
buckets="time_day_s",
avg(qtime_i)),
walk="time_day_s->time_day_s",
gather="type_s",
window="-3DAYS",
count(*)))有时您可能需要在向前或向后遍历时间时跳过周末。 这对于关联在工作日交易的金融工具非常有用。 WEEKDAYS 时间窗口将向前或向后遍历指定的工作日数。
scoreNodes(nodes(solr_logs,
facet(solr_logs,
q="+type_s:query +distrib_s:false",
buckets="time_day_s",
avg(qtime_i)),
walk="time_day_s->time_day_s",
gather="type_s",
window="-3WEEKDAYS",
count(*)))