搜索、采样和聚合
数据是统计分析中不可或缺的因素。本节概述了用于检索数据以进行可视化和统计分析的关键函数:搜索、采样和聚合。
搜索
浏览
search 函数可用于搜索 SolrCloud 集合并返回结果集。
下面是从 Zeppelin-Solr 解释器调用的最基本的 search 函数示例。Zeppelin-Solr 将 seach(logs) 调用发送到 /stream 处理程序,并以表格格式显示结果。
在该示例中,search 函数仅传递正在搜索的集合的名称。这将返回一个包含所有字段的 10 条记录的结果集。这个简单的函数对于浏览数据中的字段并了解如何开始优化搜索条件非常有用。
采样
random 函数从分布式搜索结果集中返回一个随机样本。这可以实现快速可视化、统计分析和样本建模,这些样本可用于推断有关较大结果集的信息。
下面的可视化示例使用了小的随机样本,但 Solr 的随机抽样可以在超过 200,000 个样本大小的情况下提供亚秒级的响应时间。这些较大的样本可用于构建可靠的统计模型,以亚秒级的性能描述大型数据集(数十亿个文档)。
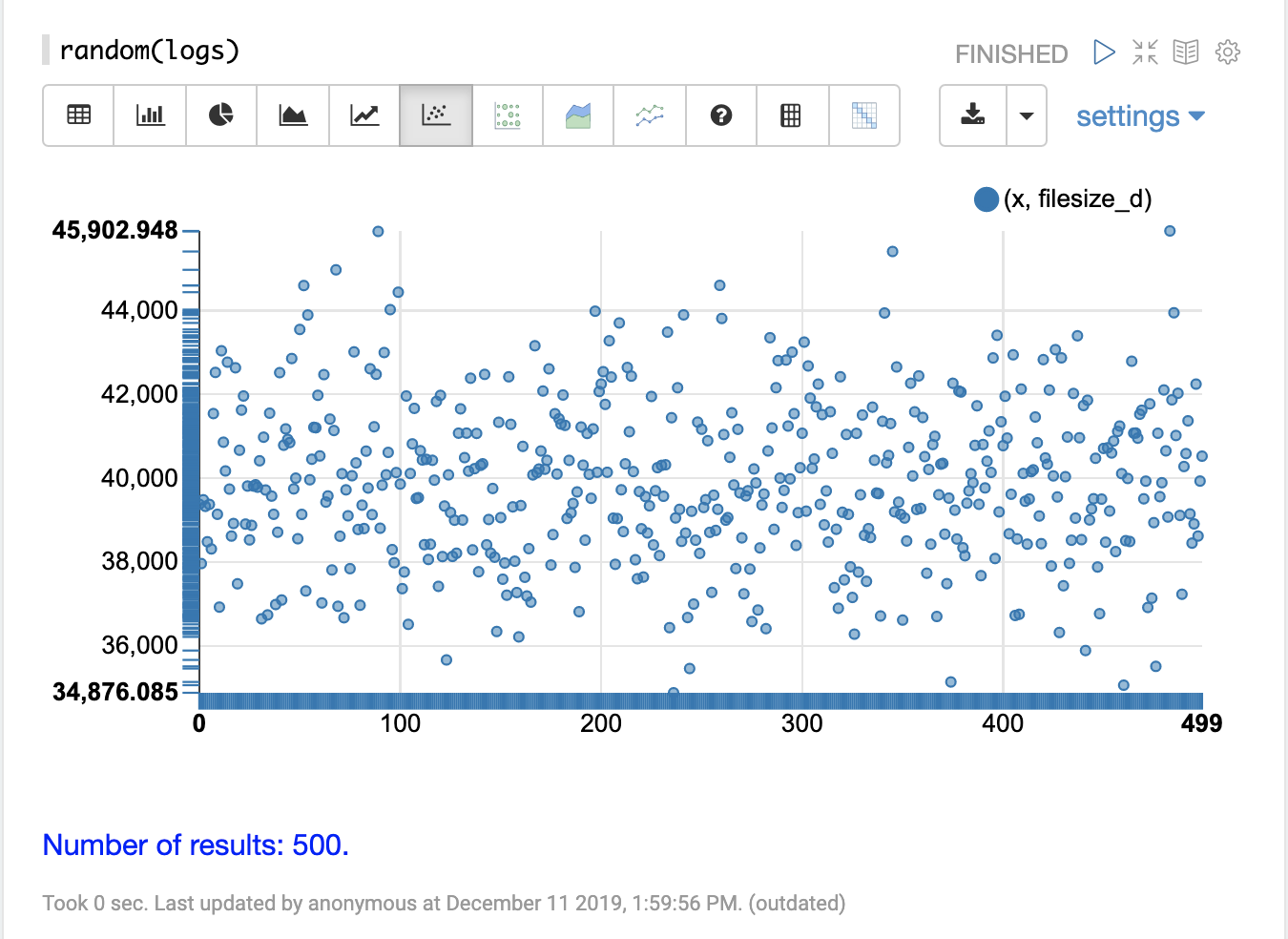
单变量散点图
在下面的示例中,random 函数以最简单的形式调用,仅使用集合名称作为参数。
当不带其他参数调用时,random 函数将返回一个包含集合中所有字段的 500 条随机记录的样本。当不带字段列表参数(fl)调用时,random 函数还会生成一个序列,在本例中为 0-499,该序列可用于绘制 x 轴。此序列在名为 x 的字段中返回。
下面的可视化显示了一个散点图,其中 filesize_d 字段绘制在 y 轴上,x 序列绘制在 x 轴上。这样做的效果是将 filesize_d 样本分散在整个图的长度上,以便更容易研究它们。
通过研究散点图,我们可以了解有关 filesize_d 变量分布的许多信息
-
样本集范围从 34,875 到 45,902。
-
最高密度似乎在 40,000 左右。
-
该样本在 40,000 以上和以下似乎具有平衡的观测值数量。基于此,平均值和众数似乎在 40,000 左右。
-
观测值的数量逐渐减少到样本低端和高端的一小部分异常值。
可以多次重新运行此样本,以查看样本是否产生相似的图。
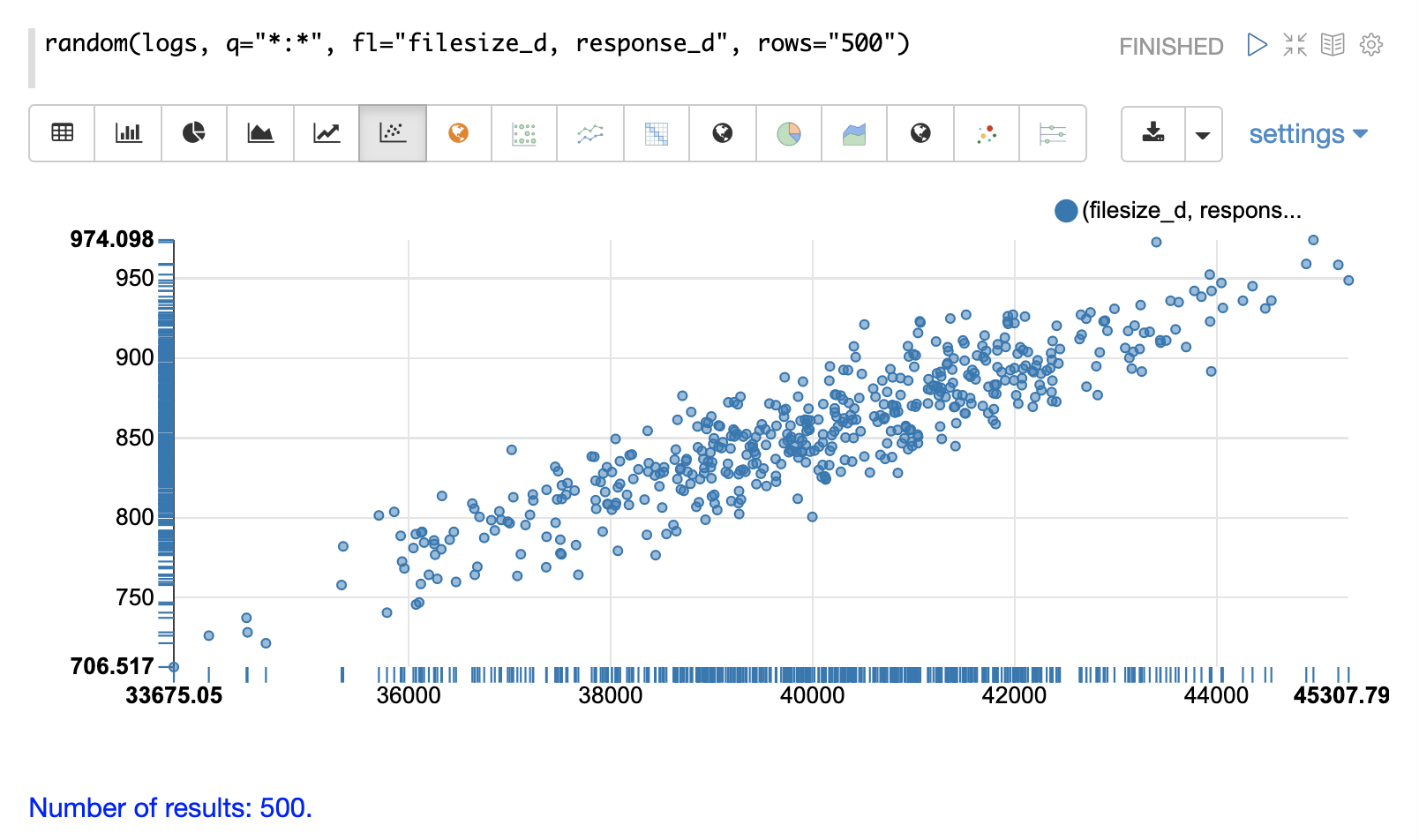
双变量散点图
在下一个示例中,已将参数添加到 random 函数中。字段列表 (fl) 现在指定每个样本返回两个字段:filesize_d 和 response_d。q 和 rows 参数与默认值相同,但作为如何设置这些参数的示例包含在内。
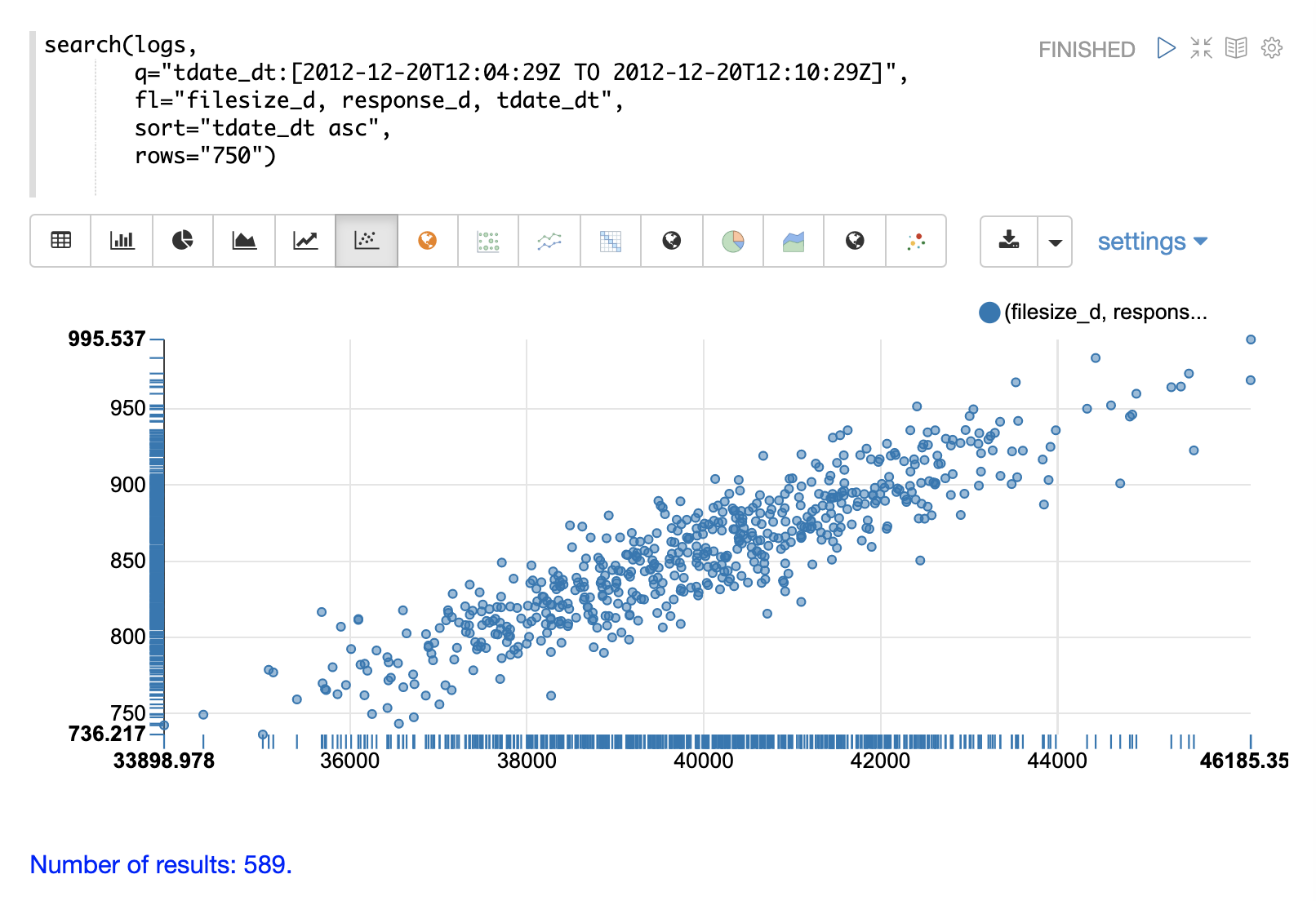
通过在 x 轴上绘制 filesize_d,在 y 轴上绘制 response_d,我们可以开始研究这两个变量之间的关系。
通过研究散点图,我们可以了解以下内容
-
随着
filesize_d的升高,response_d倾向于升高。 -
这种关系似乎是线性的,因为可以使用穿过数据的直线来建模这种关系。
-
这些点似乎沿着中间的直线更加密集地聚集,并且随着它们远离直线而变得不那么密集。
-
每个
filesize_d点的数据方差似乎相当一致。这意味着预测模型在整个预测范围内将具有一致的误差。
聚合
聚合是用于汇总大型数据集并呈现数据中的模式、趋势和相关性的强大统计工具。聚合也是可视化的强大工具,并为进一步的统计分析提供数据集。
stats
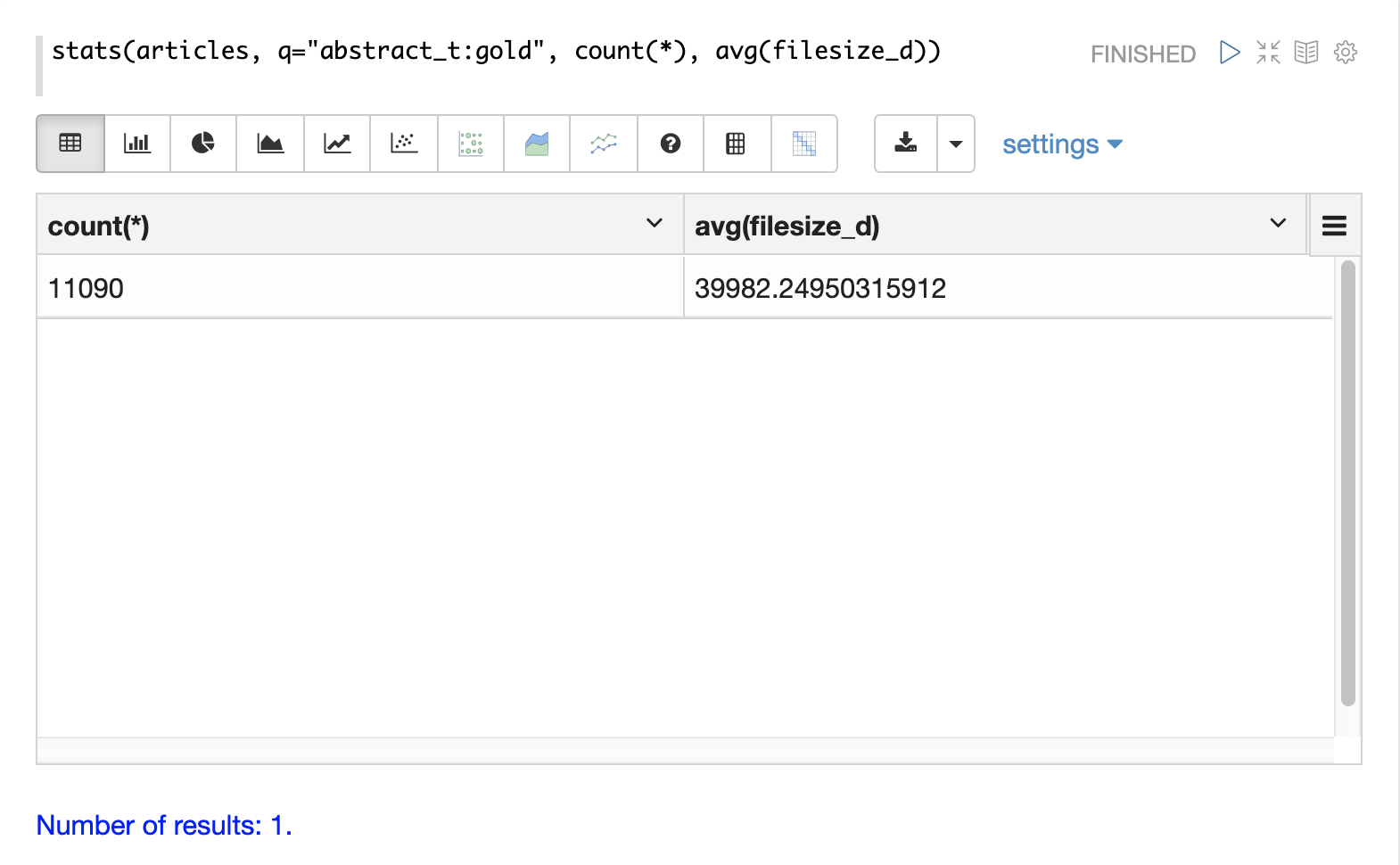
最简单的聚合是 stats 函数。stats 函数计算与查询匹配的整个结果集的聚合。stats 函数支持以下聚合函数:count(*)、sum、min、max 和 avg。可以在单个函数调用中计算任意数量和组合的统计信息。
stats 函数可以在 Zeppelin-Solr 中可视化为表格。在下面的示例中,在结果集上计算两个统计信息,并将其显示在表格中
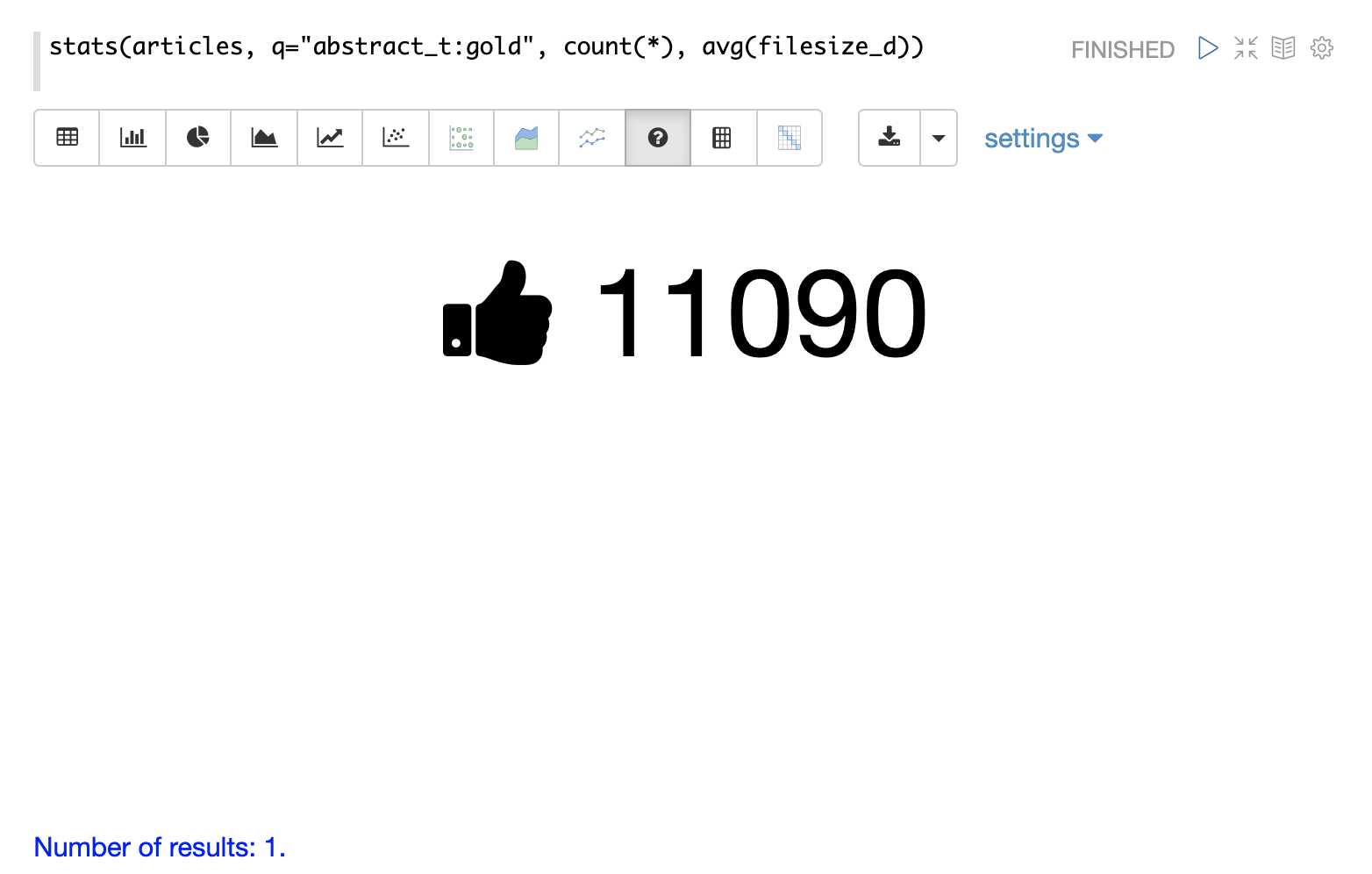
stats 函数也可以使用 number 可视化进行可视化,该可视化用于突出显示重要的数字。下面的示例显示了以数字可视化显示的 count(*) 聚合
facet
facet 函数执行单维度和多维度聚合,其行为方式与 SQL group by 聚合类似。在底层,facet 函数将聚合下推到 Solr 的 JSON Facet API 以进行快速分布式执行。
下面的示例从 nyc311(纽约市投诉)数据集执行单维度聚合。该聚合按 count 返回状态为 Pending 的记录的前五种 投诉类型。结果在 Zeppelin-Solr 中以表格形式显示。
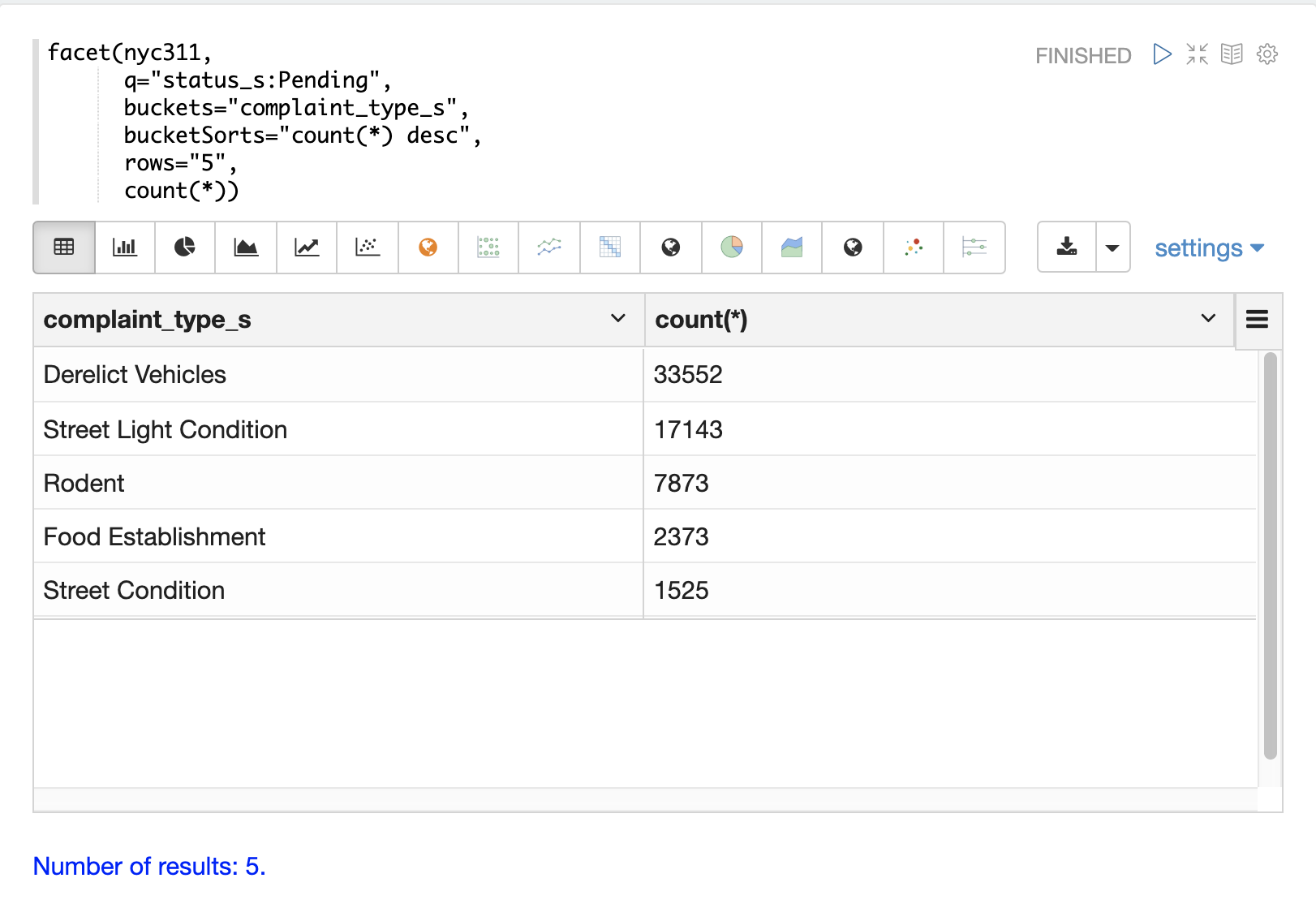
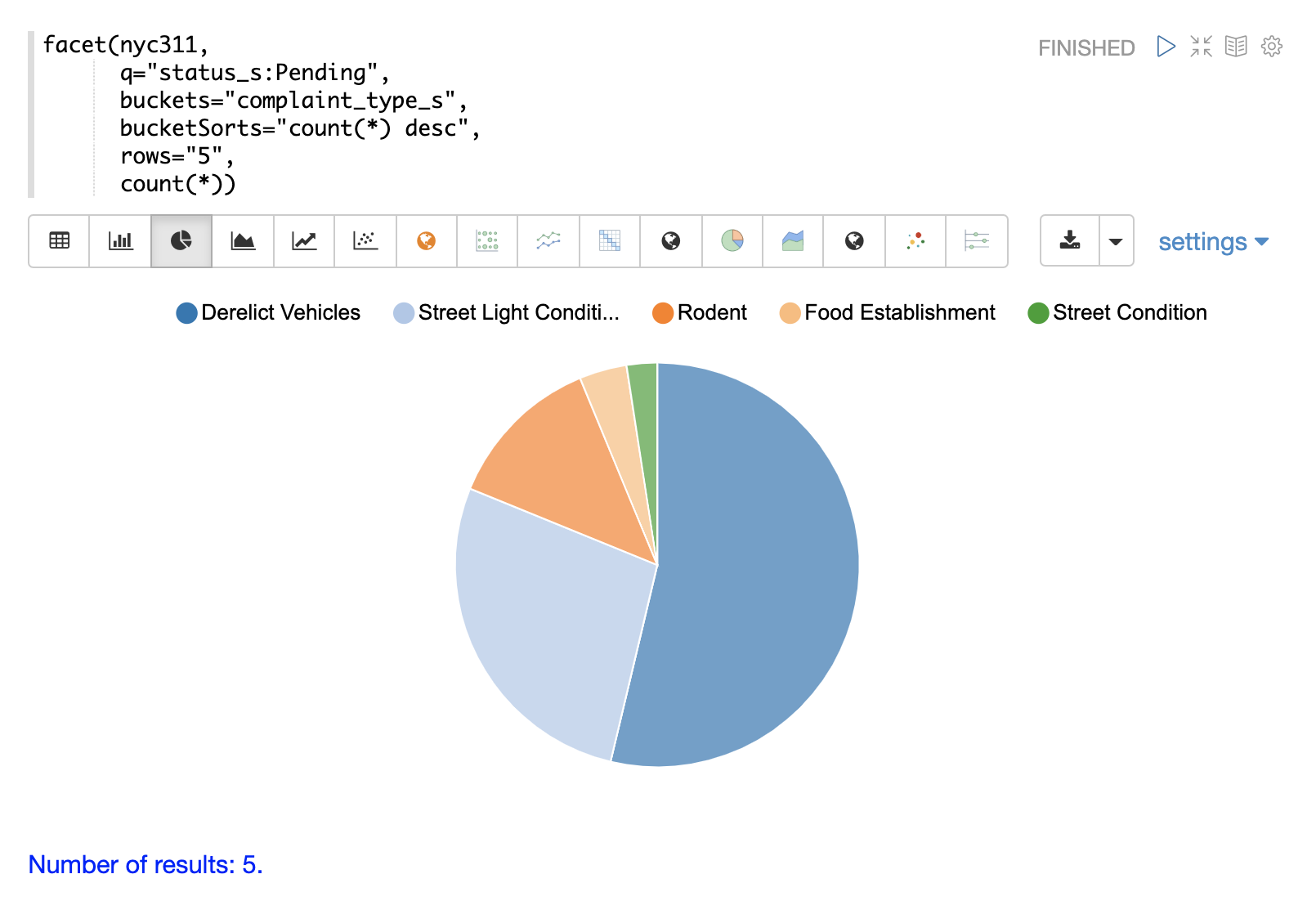
下面的示例显示了使用饼图可视化的表格。
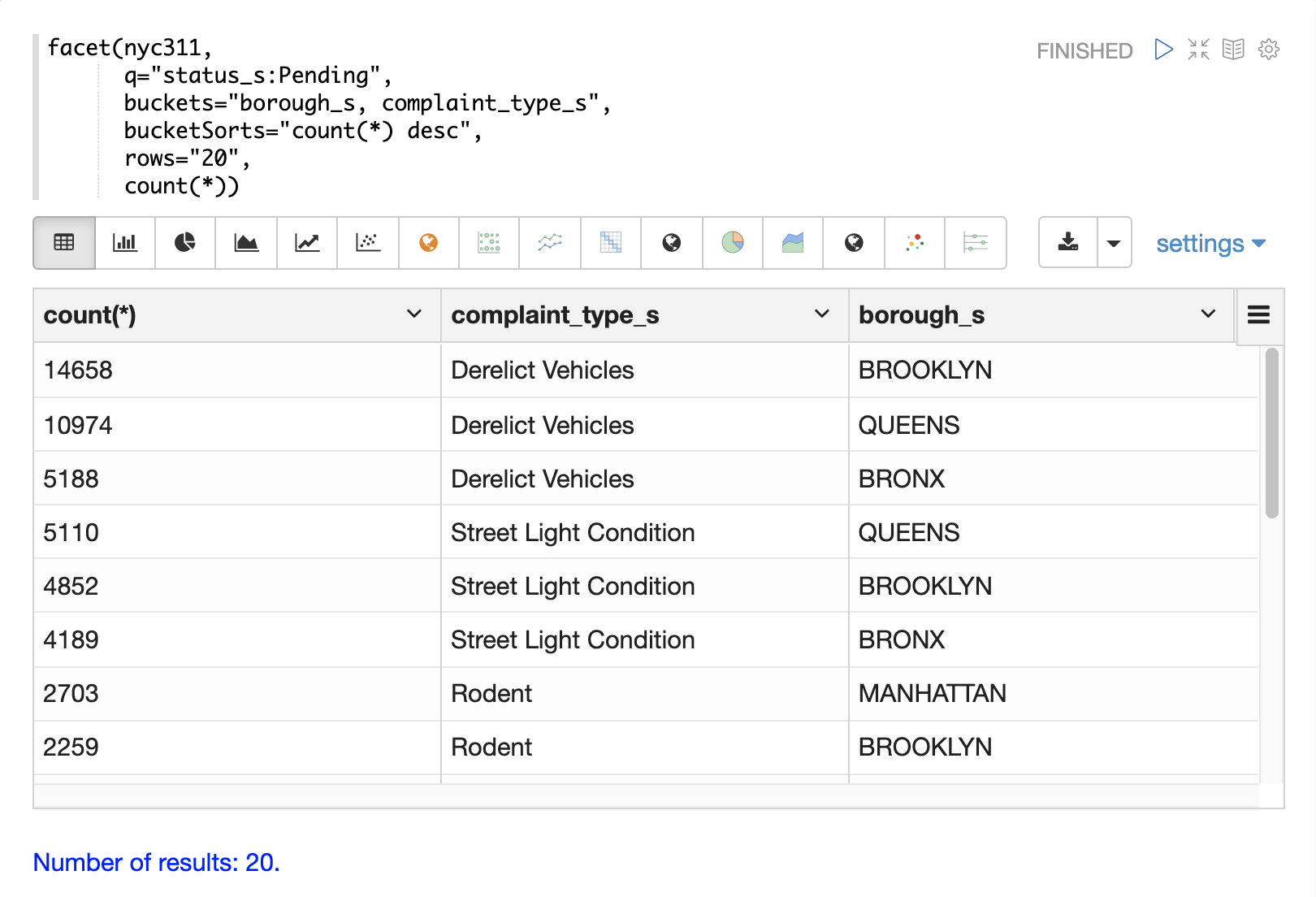
下一个示例演示了多维度聚合。请注意,buckets 参数现在包含两个维度:borough_s 和 complaint_type_s。这将按计数返回前 20 个区和投诉类型组合。
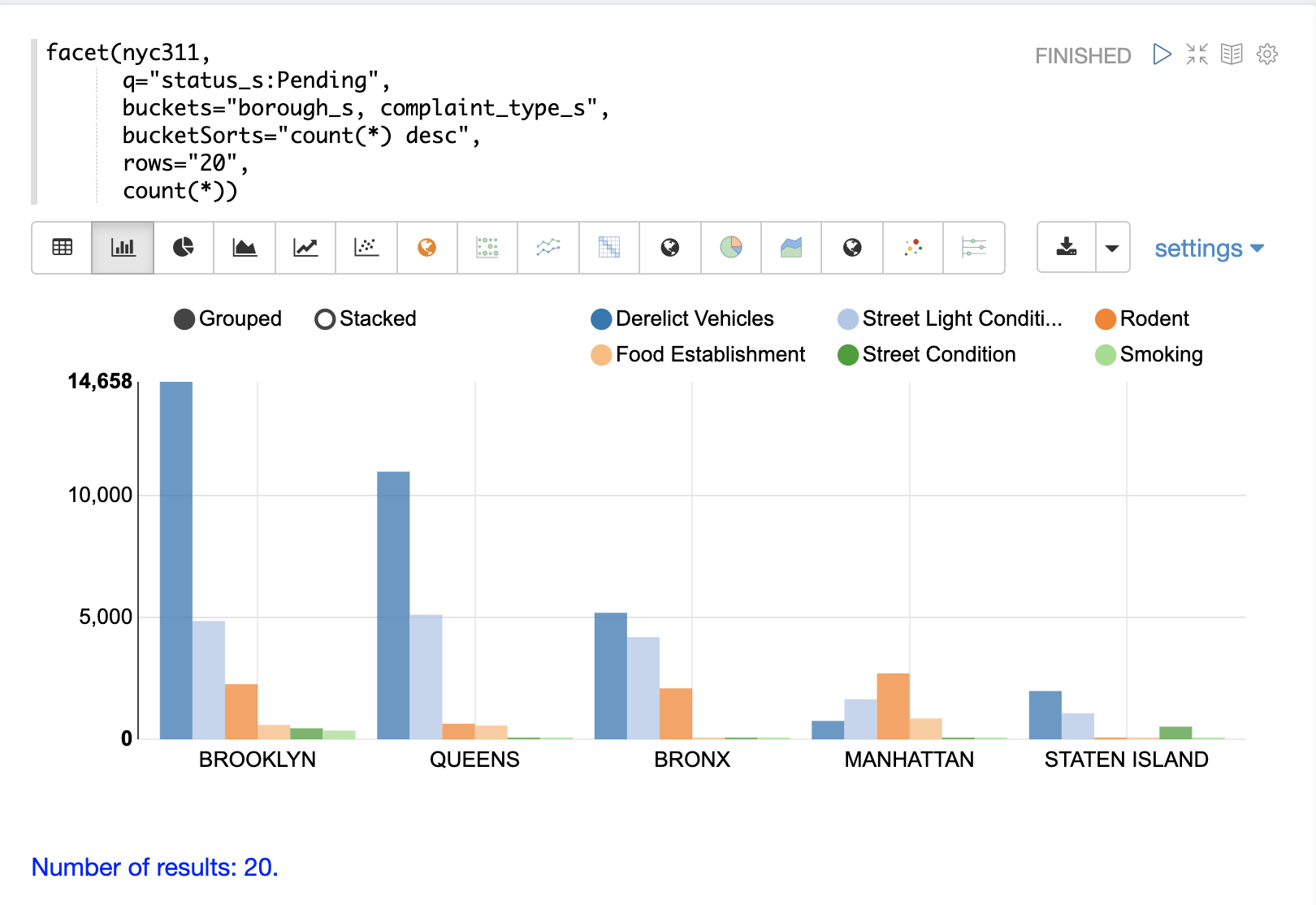
下面的示例显示了可视化为分组条形图的多维度聚合。
facet 函数支持以下聚合函数的任意组合:count(*)、sum、avg、min、max。
facet2D
facet2D 函数执行二维聚合,可以将其可视化为热图或透视为矩阵,并由机器学习函数进行操作。
facet2D 具有与二维 facet 函数不同的语法和行为,后者不控制每个维度的唯一 facets 的数量。facet2D 函数具有 dimensions 参数,该参数控制 x 和 y 维度的唯一 facets 的数量。
下面的示例可视化了 facet2D 函数的输出。在该示例中,facet2D 返回前 5 个区和每个区的前 5 个投诉类型。然后将输出可视化为热图。
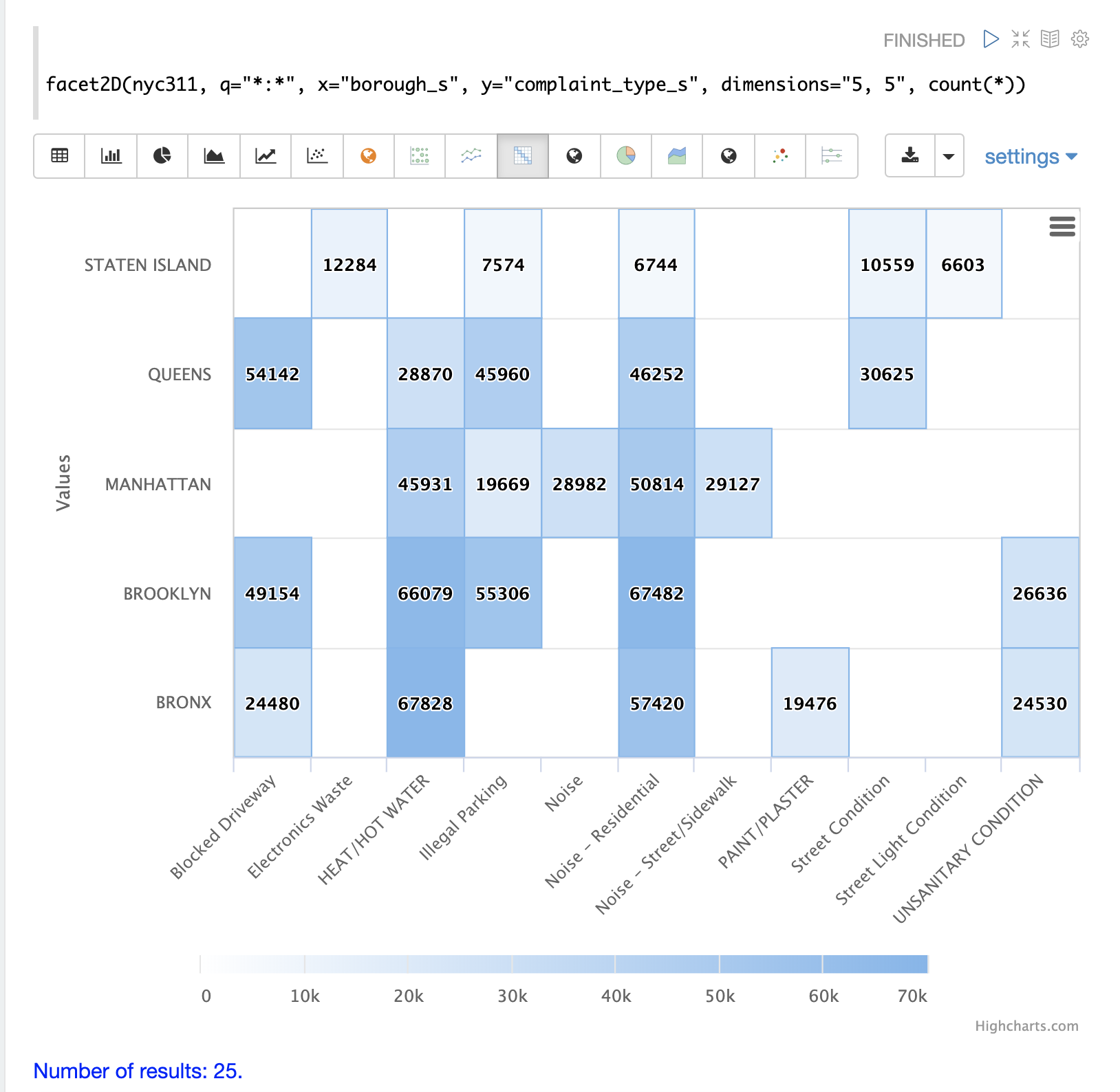
facet2D 函数支持以下聚合函数之一:count(*)、sum、avg、min、max。
timeseries
timeseries 函数利用 Solr 的内置分面和日期数学功能执行快速、分布式的时序聚合。
下面的示例在每日股票价格数据集合上执行每月时序聚合。在此示例中,计算特定日期范围内股票代码 amzn 的每月平均收盘价。
然后使用折线图可视化 timeseries 函数的输出。
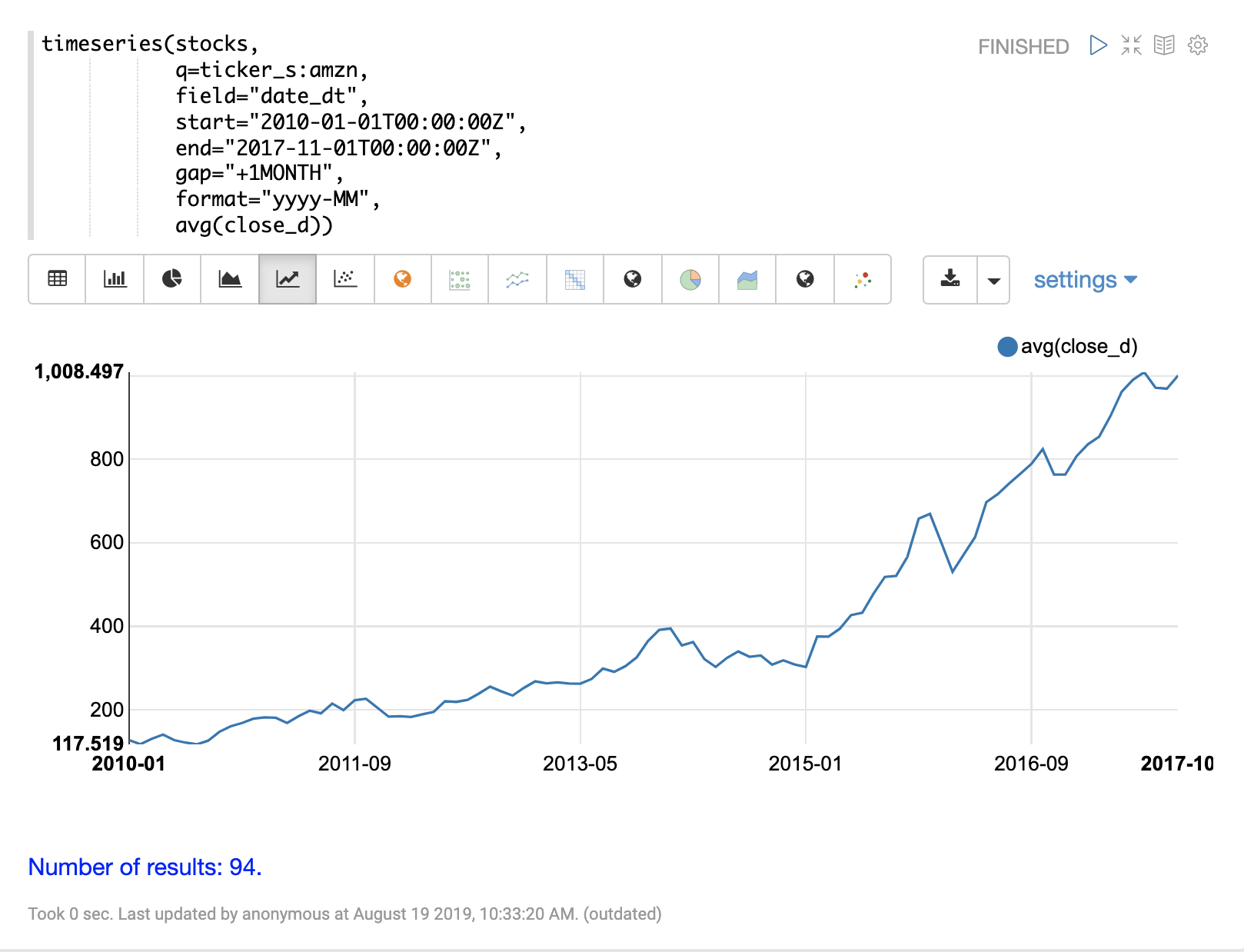
timeseries 函数支持以下聚合函数的任意组合:count(*)、sum、avg、min、max。
significantTerms
significantTerms 函数查询集合,但不是返回文档,而是返回在结果集中文档中找到的重要术语。此函数根据术语在结果集中出现的频率以及在整个语料库中出现的频率来评分术语。significantTerms 函数为每个术语发出一个元组,其中包含术语、分数、前景计数和背景计数。前景计数是该术语在结果集中出现的文档数。背景计数是该术语在整个语料库中出现的文档数。前景计数和背景计数对于集合是全局的。
significantTerms 函数通常可以提供从其他类型的聚合中无法收集到的见解。下面的示例说明了 facet 函数和 significantTerms 函数之间的区别。
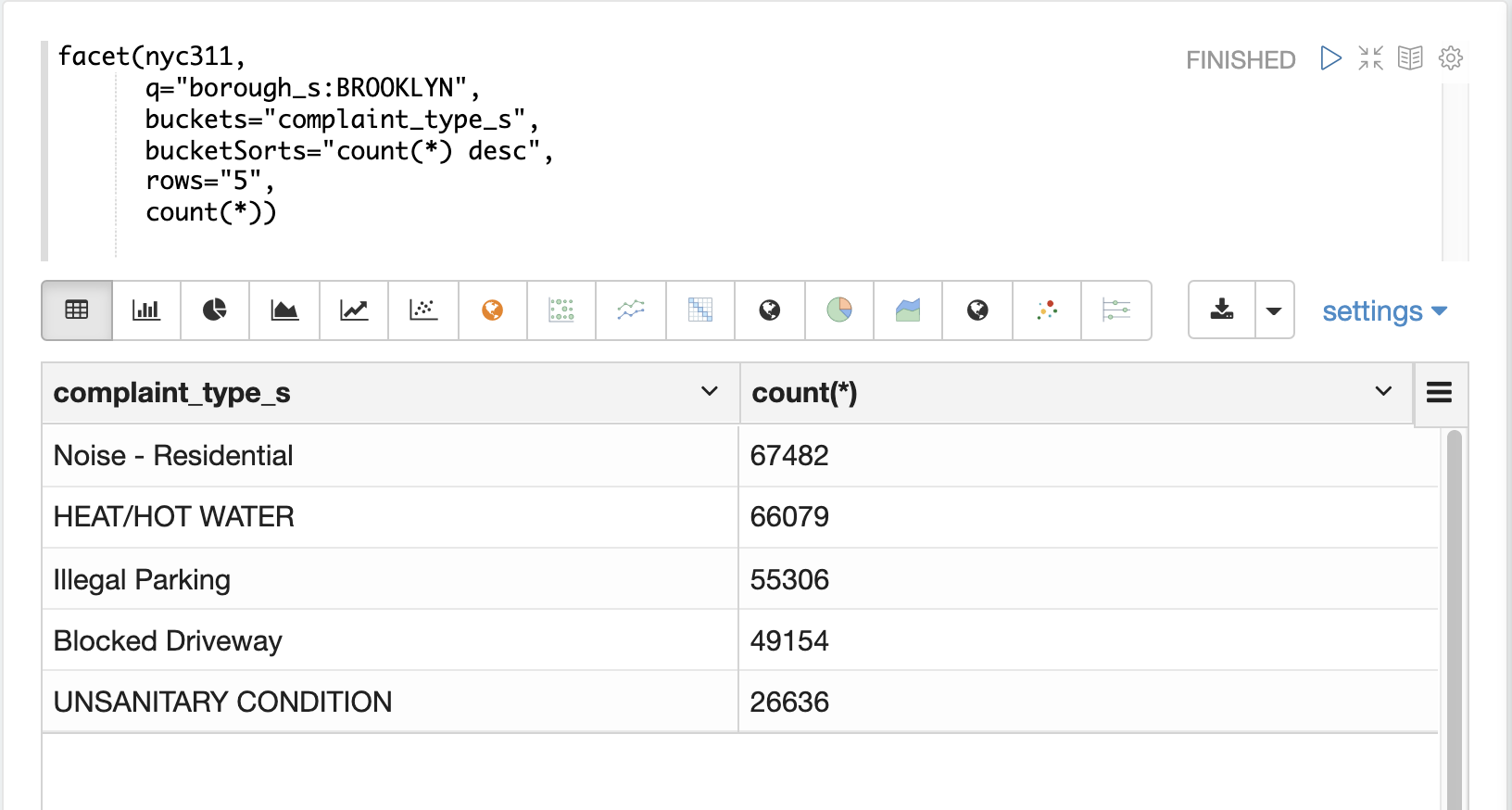
在第一个示例中,facet 函数聚合布鲁克林的前 5 种投诉类型。这将返回布鲁克林最常见的五种投诉类型,但不清楚这些术语在布鲁克林中出现的频率是否比其他行政区更高。
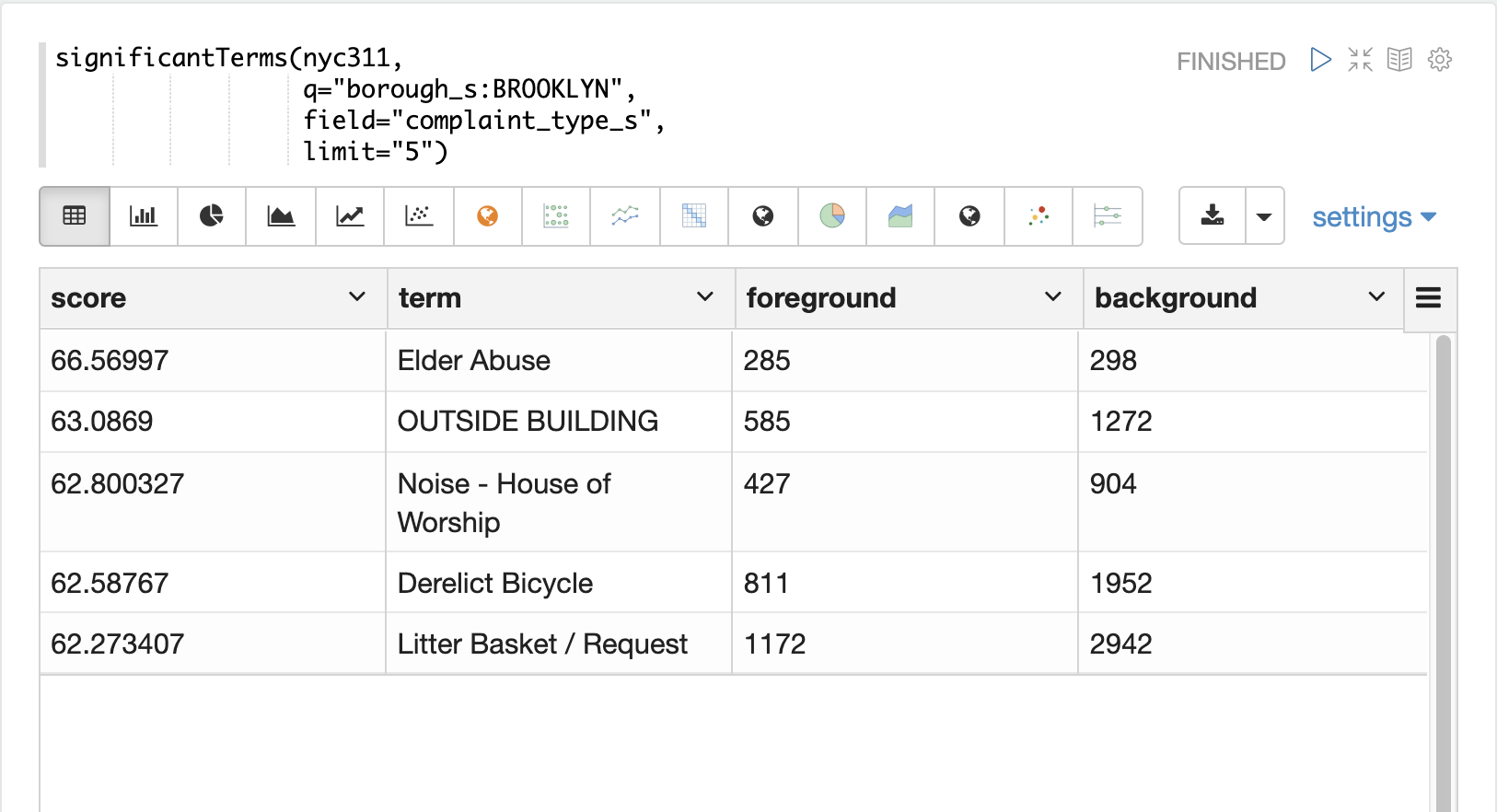
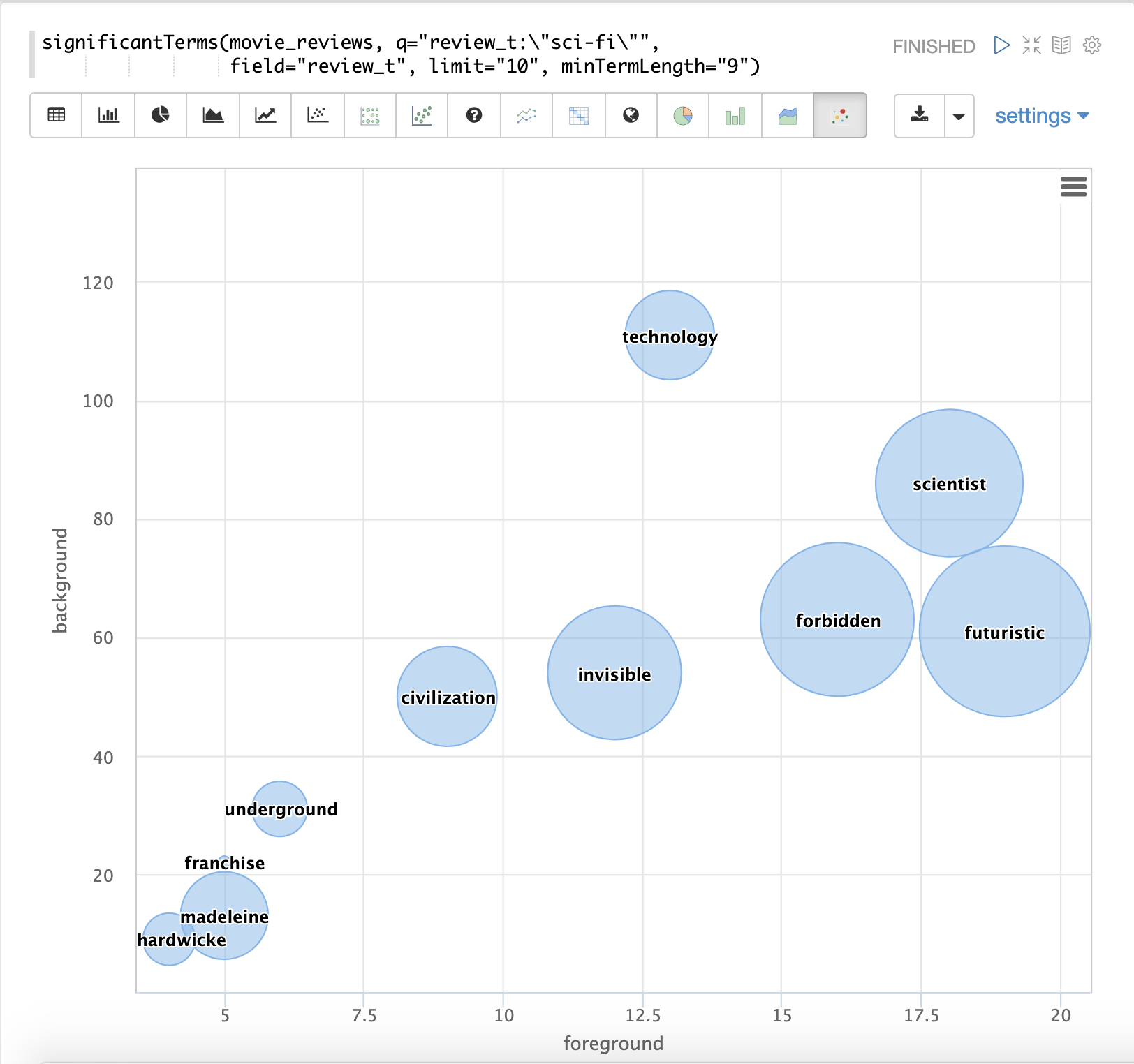
在下一个示例中,significantTerms 函数返回布鲁克林行政区的 complaint_type_s 字段中前 5 个重要术语。得分最高的术语“虐待老人”的前景计数为 285,背景计数为 298。这意味着整个数据集中有 298 起虐待老人投诉,其中 285 起在布鲁克林。这表明虐待老人投诉在布鲁克林的发生率远高于其他行政区。
最后一个示例显示了来自包含电影评论的文本字段的 significantTerms 的可视化。结果显示了在包含短语“科幻”的电影评论中出现的重要术语。
结果使用气泡图进行可视化,其中 前景 计数绘制在 x 轴上,背景 计数绘制在 y 轴上。每个术语都以按 分数 大小调整的气泡显示。
nodes
nodes 函数在图的广度优先搜索期间执行节点的聚合。本节将在 图遍历 部分中详细介绍此函数。在本示例中,重点将是使用 nodes 表达式在时间序列图中查找相关节点。
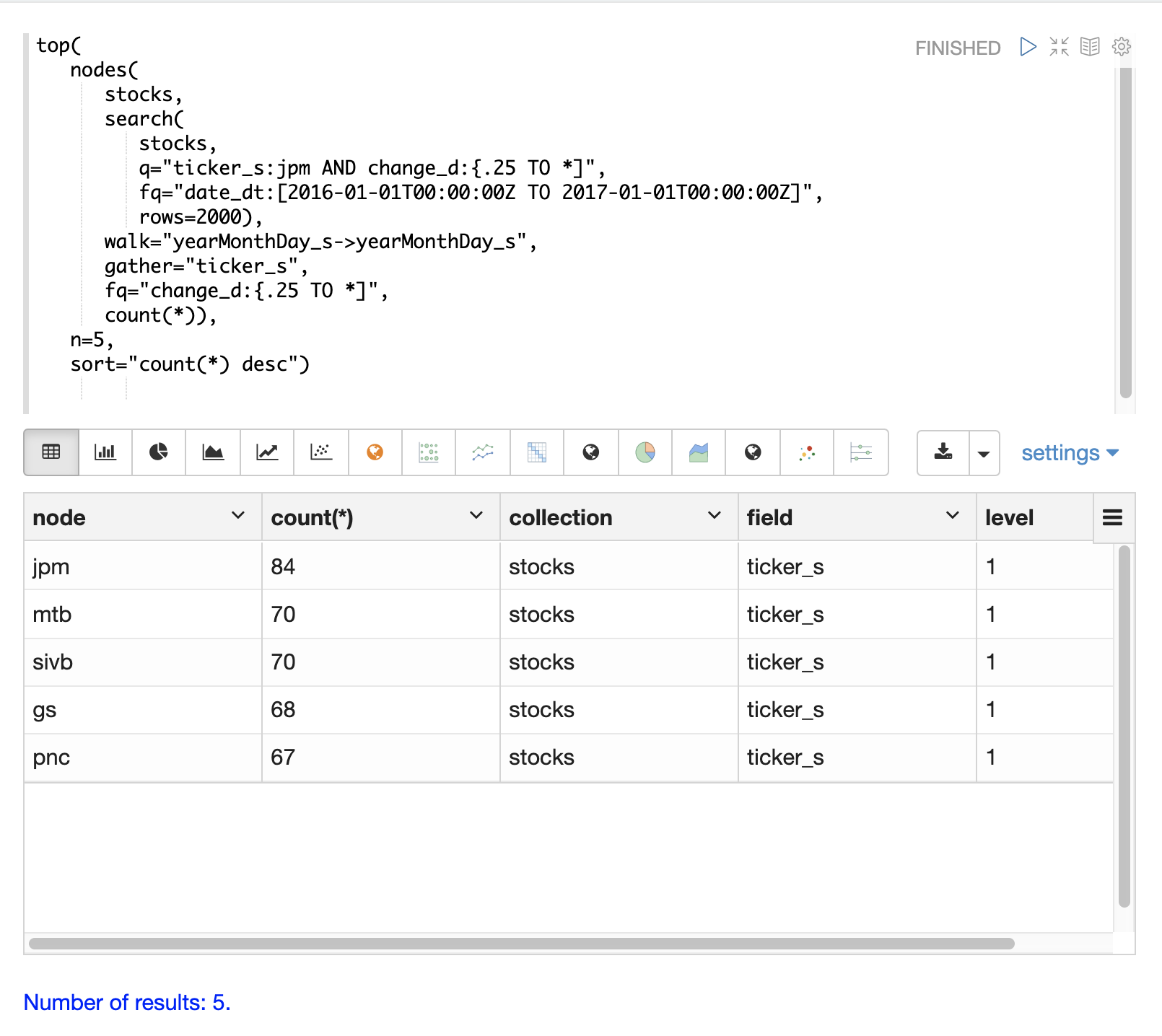
下面的示例查找其每日变动趋势与股票代码 jpm (摩根大通) 相关的股票代码。
内部 search 表达式查找在特定日期范围内股票代码为 jpm 且 change_d 字段(股票价格的每日变动)大于 0.25 的记录。此搜索返回索引中的所有字段,包括 yearMonthDay_s,它是匹配记录的年、月和日的字符串表示形式。
nodes 函数封装了 search 函数,并在其结果上进行操作。walk 参数将搜索结果中的一个字段映射到索引中的一个字段。在本例中,yearMonthDay_s 被映射回同一索引中的 yearMonthDay_s 字段。这将查找与初始搜索返回的 yearMonthDay_s 字段值相同的记录,并返回这些日期上所有股票代码的记录。搜索时应用了一个过滤查询,以将搜索范围缩小到 change_d 大于 0.25 的行。这将查找匹配日期上所有日变化大于 0.25 的记录。
gather 参数告诉 nodes 表达式在广度优先搜索期间收集 ticker_s 代码。count(*) 参数计算股票代码出现的次数。这将计算每个股票代码在广度优先搜索中出现的次数。
最后,top 函数选择计数最高的 5 个股票代码并返回它们。
下面的结果显示了 nodes 字段中的股票代码以及每个节点的计数。请注意,jpm 排在第一位,这显示了在此时段内 jpm 有多少天的变化大于 0.25。接下来的股票代码集合(mtb、slvb、gs 和 pnc)是在 jpm 变化大于 0.25 的同一天,变化大于 0.25 的天数最多的股票代码。
nodes 函数支持以下聚合函数的任意组合:count(*)、sum、avg、min、max。