概率分布
用户指南的这一部分介绍了数学表达式库中包含的概率分布框架。
可视化
可以使用 Zeppelin-Solr 的 zplot 函数和 dist 参数可视化概率分布,该参数可视化分布的概率密度函数 (PDF)。
下面的每个分布都显示了示例可视化。
连续分布
连续概率分布适用于连续数字(浮点数)。以下是支持的连续概率分布。
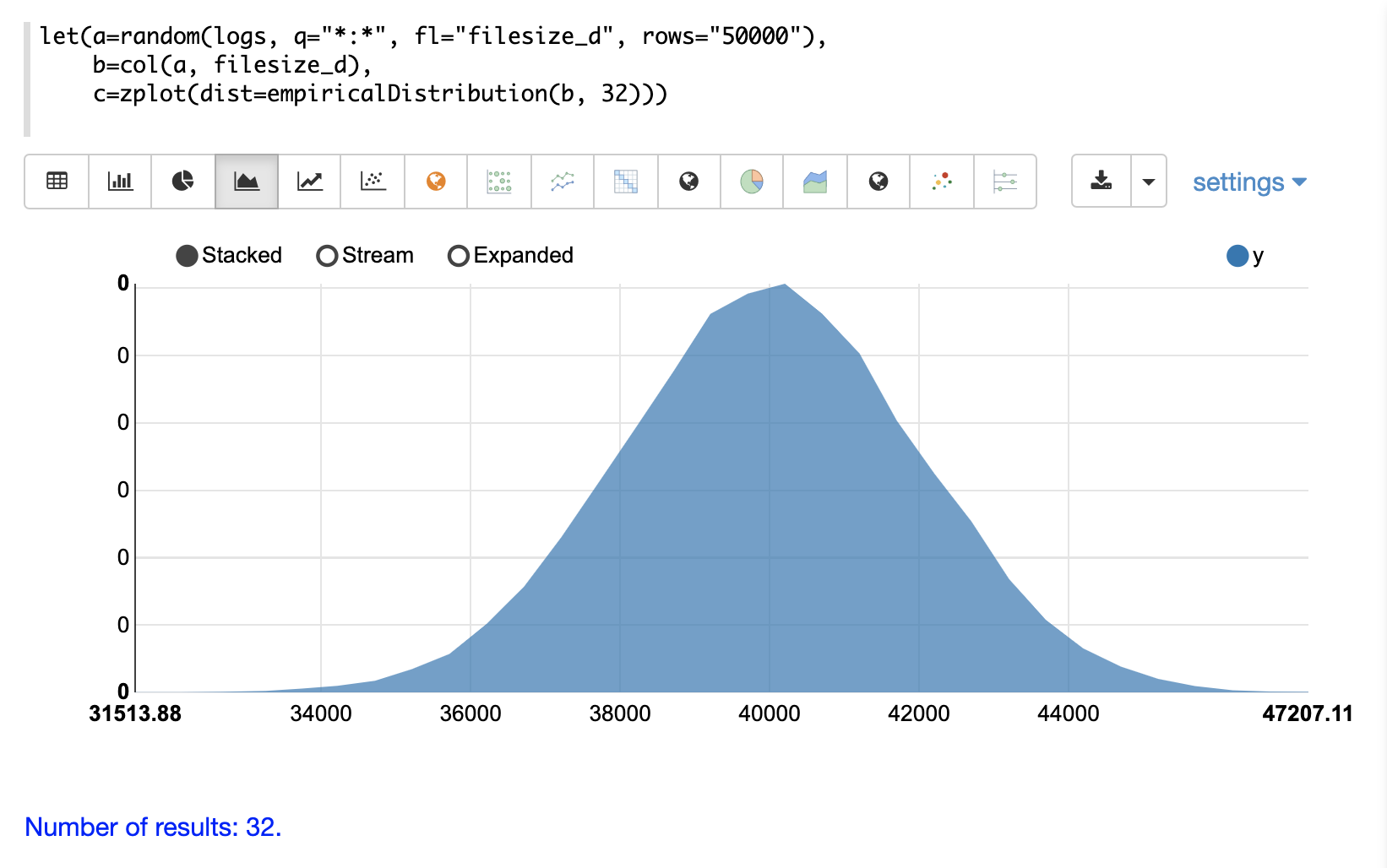
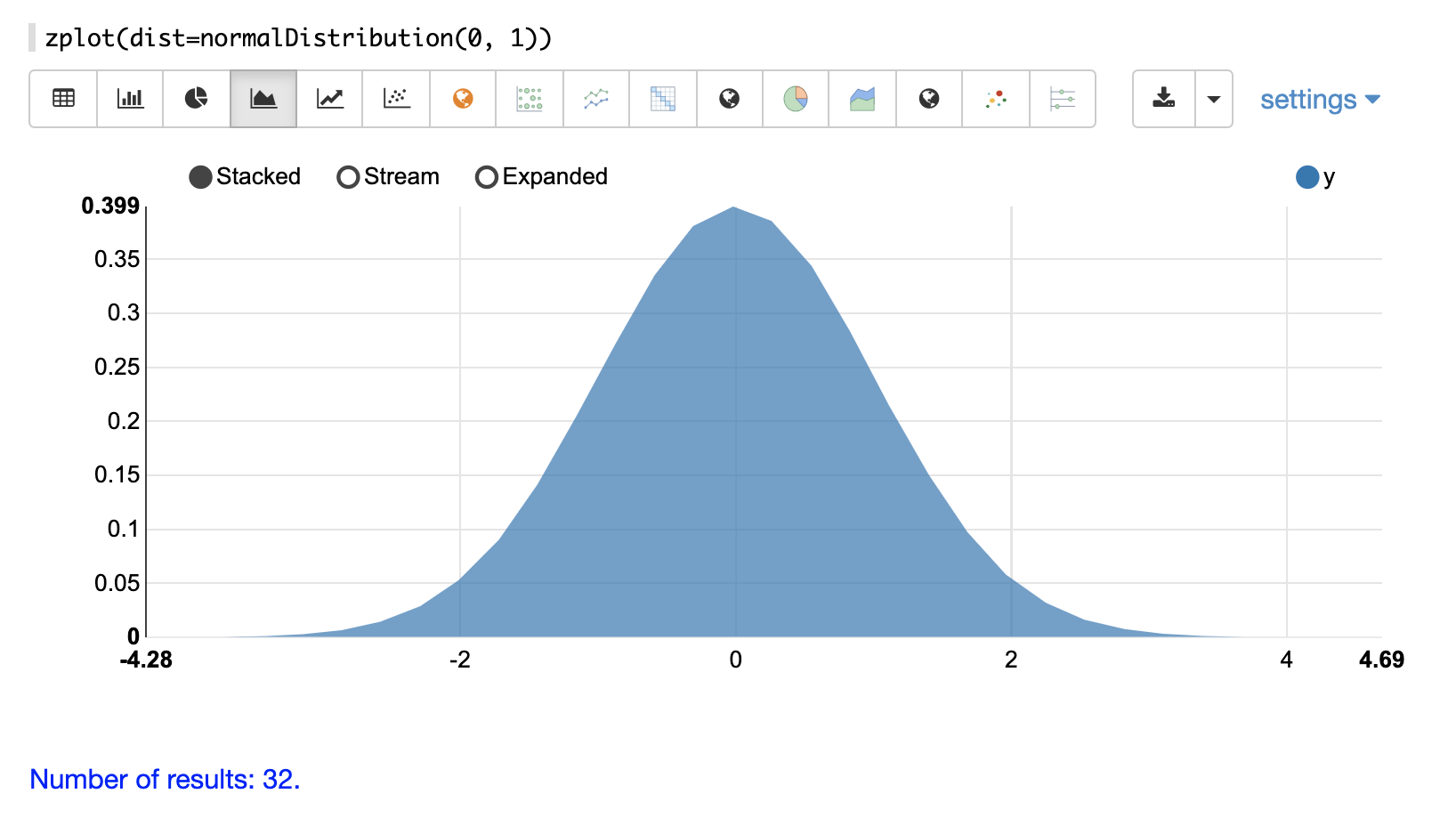
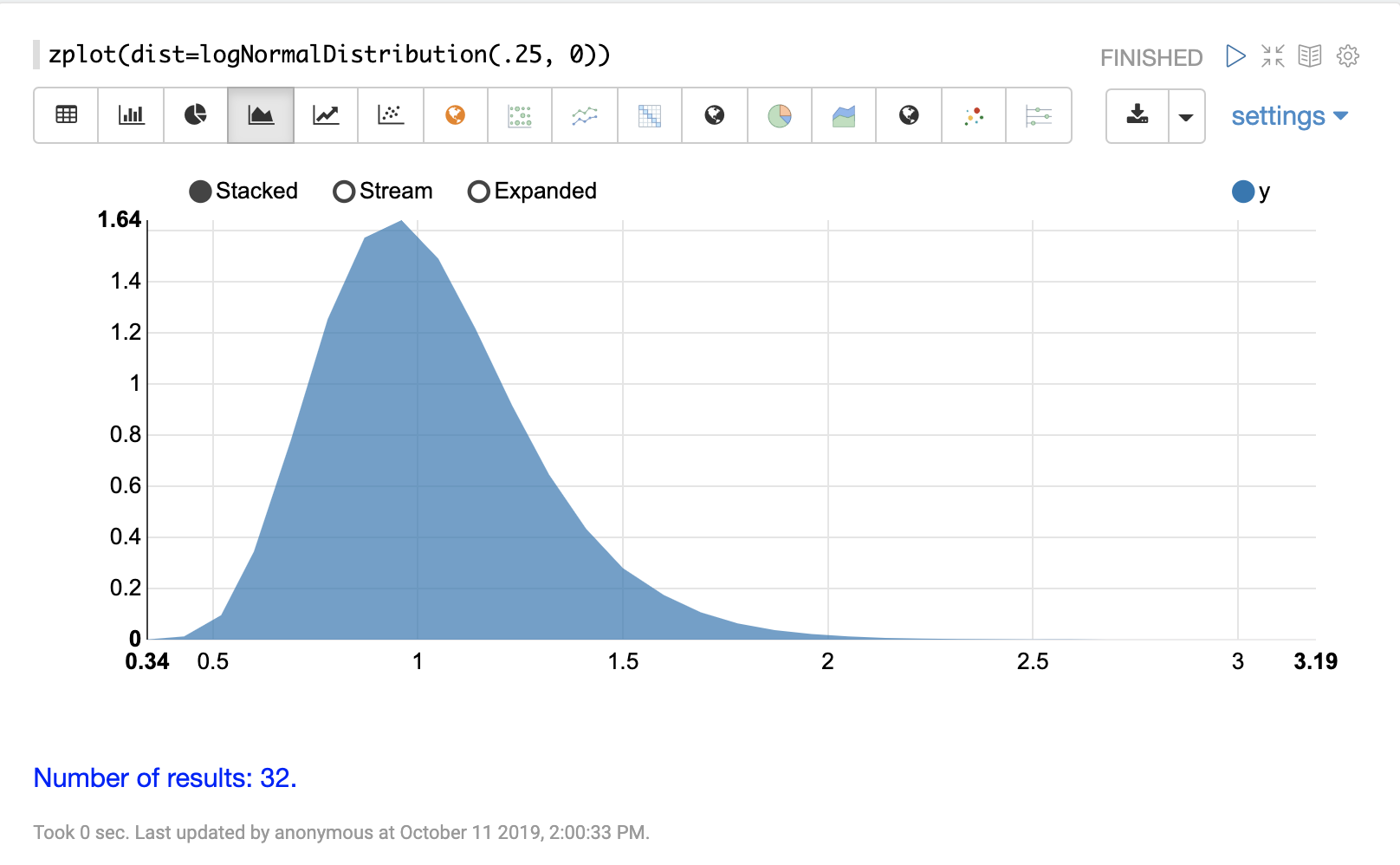
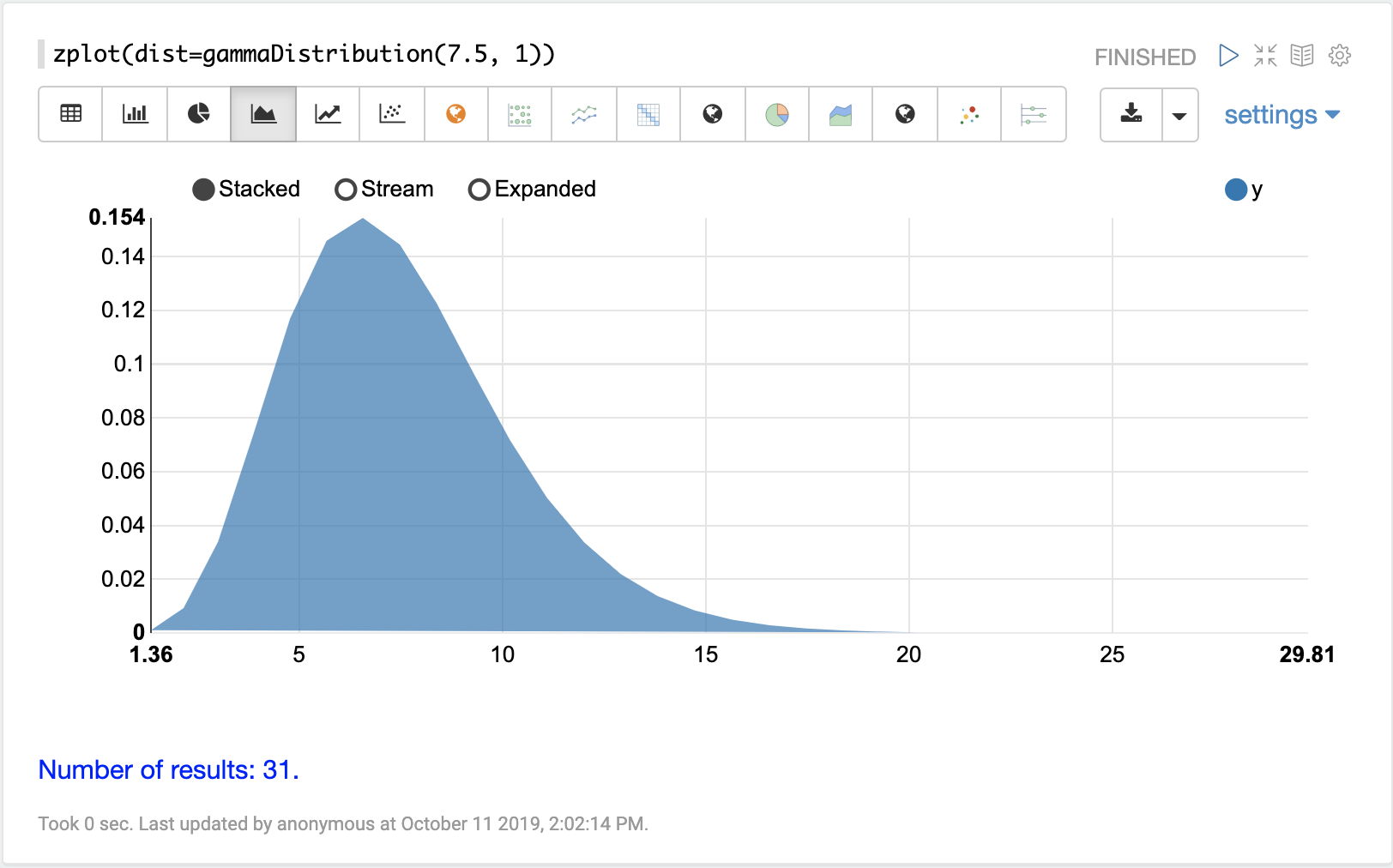
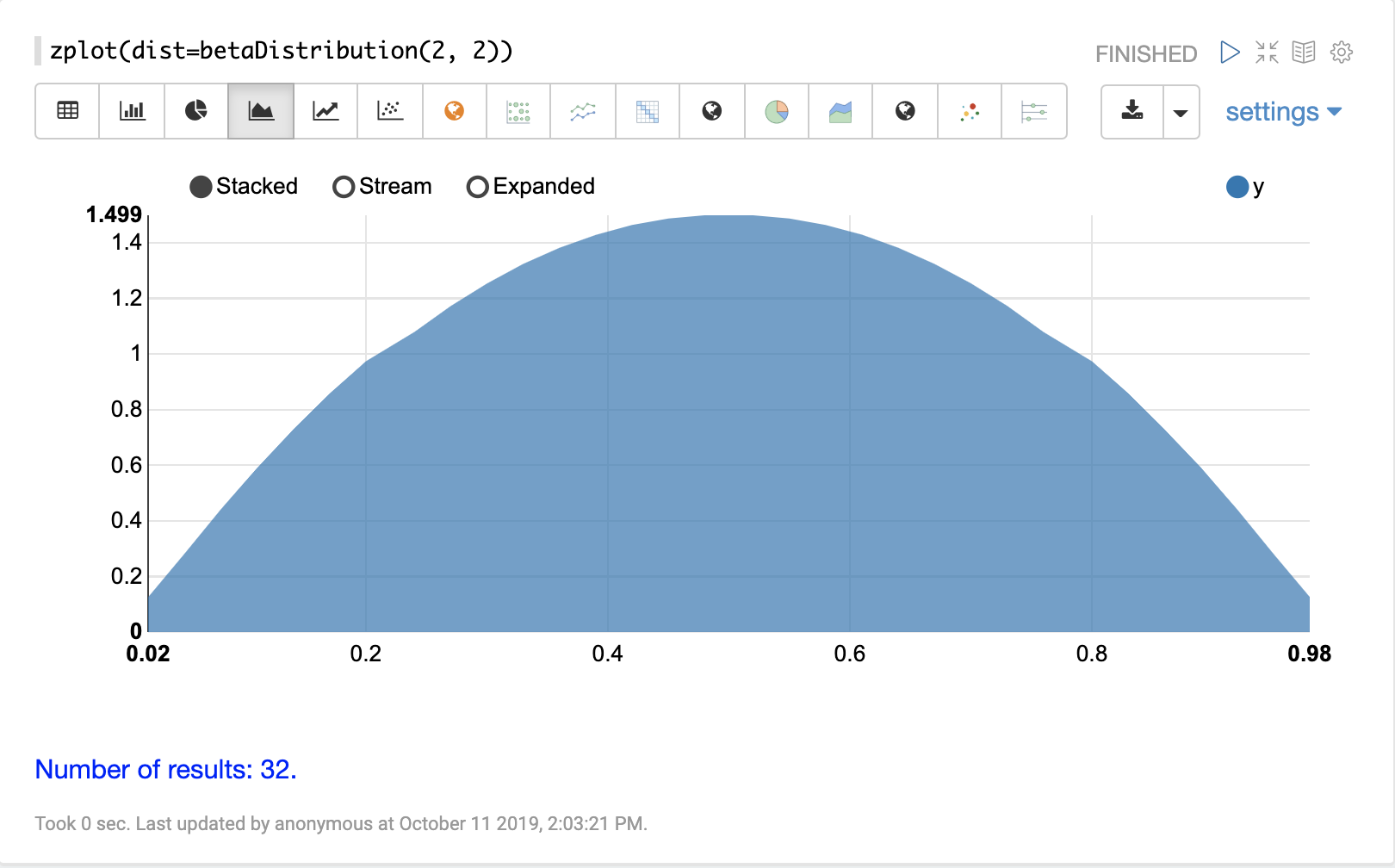
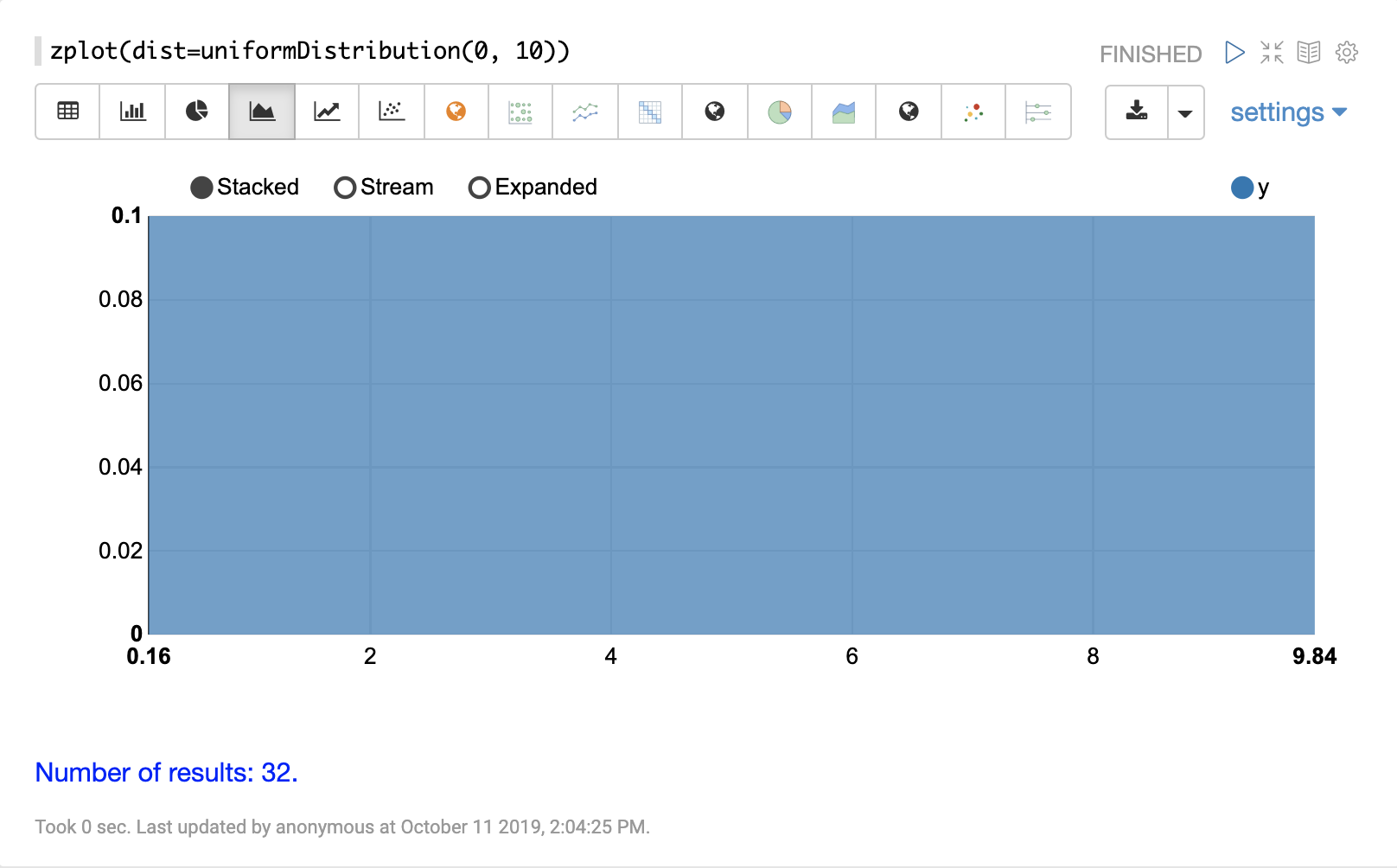
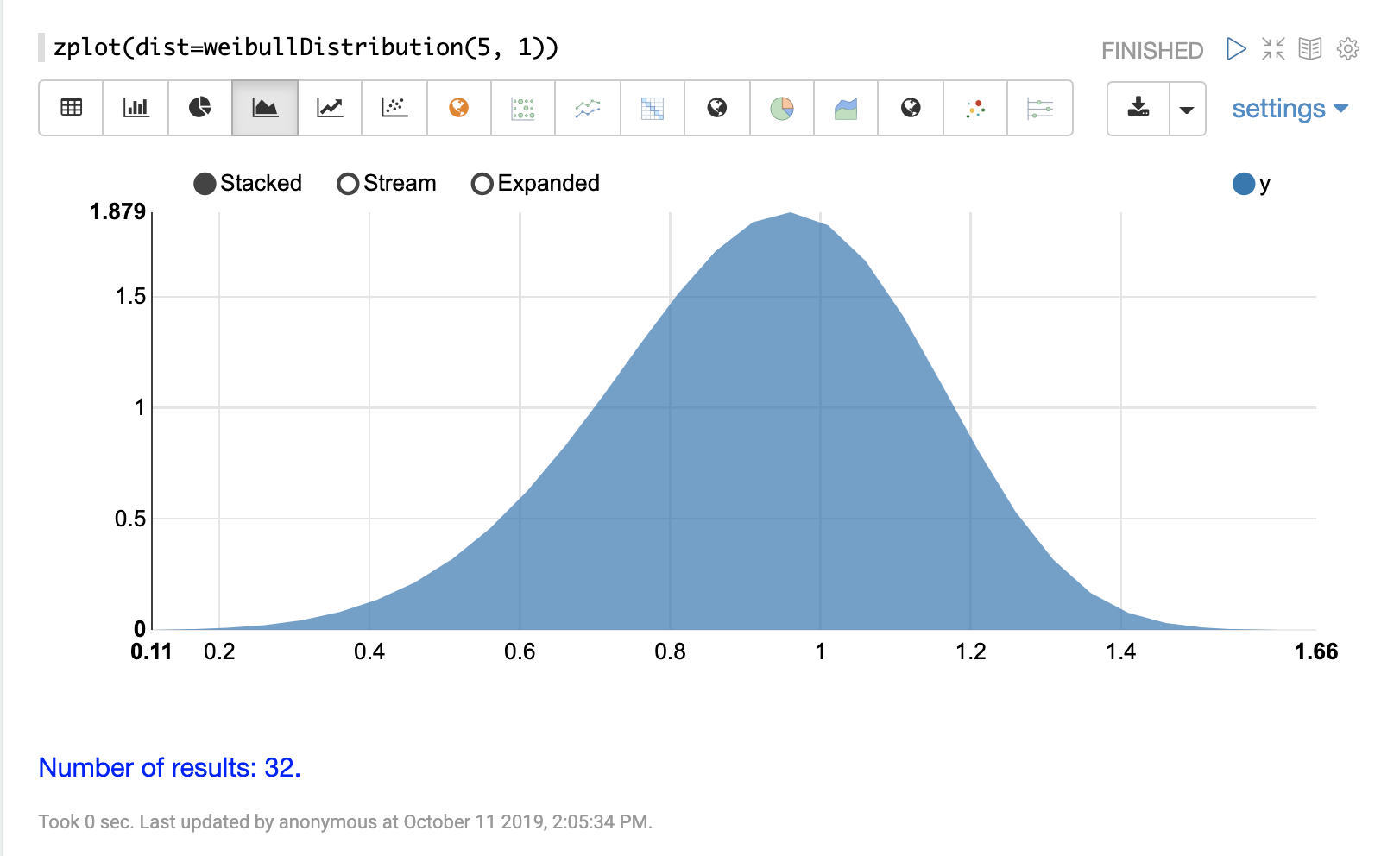
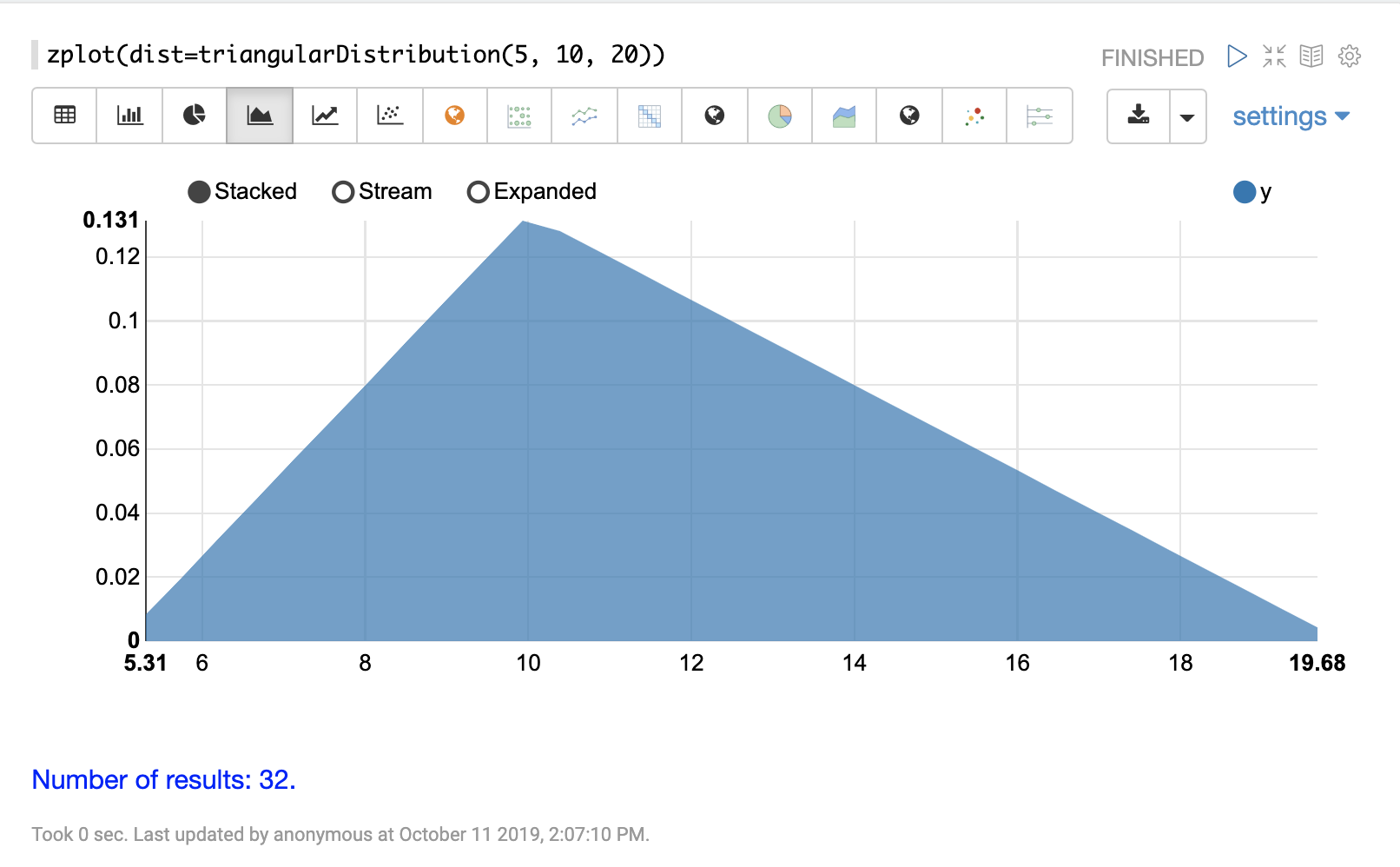
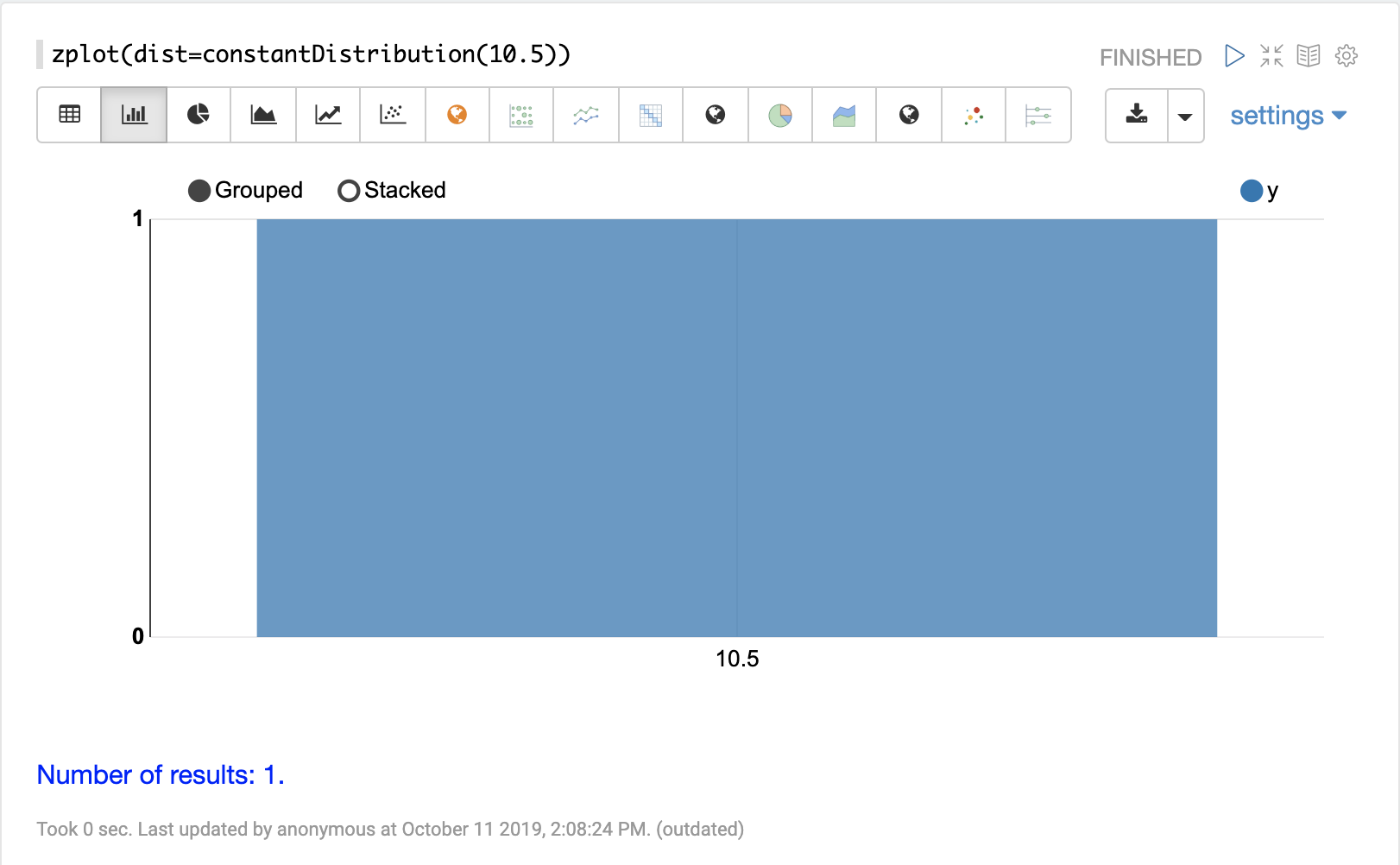
离散分布
离散概率分布适用于离散数字(整数)。以下是支持的离散概率分布。
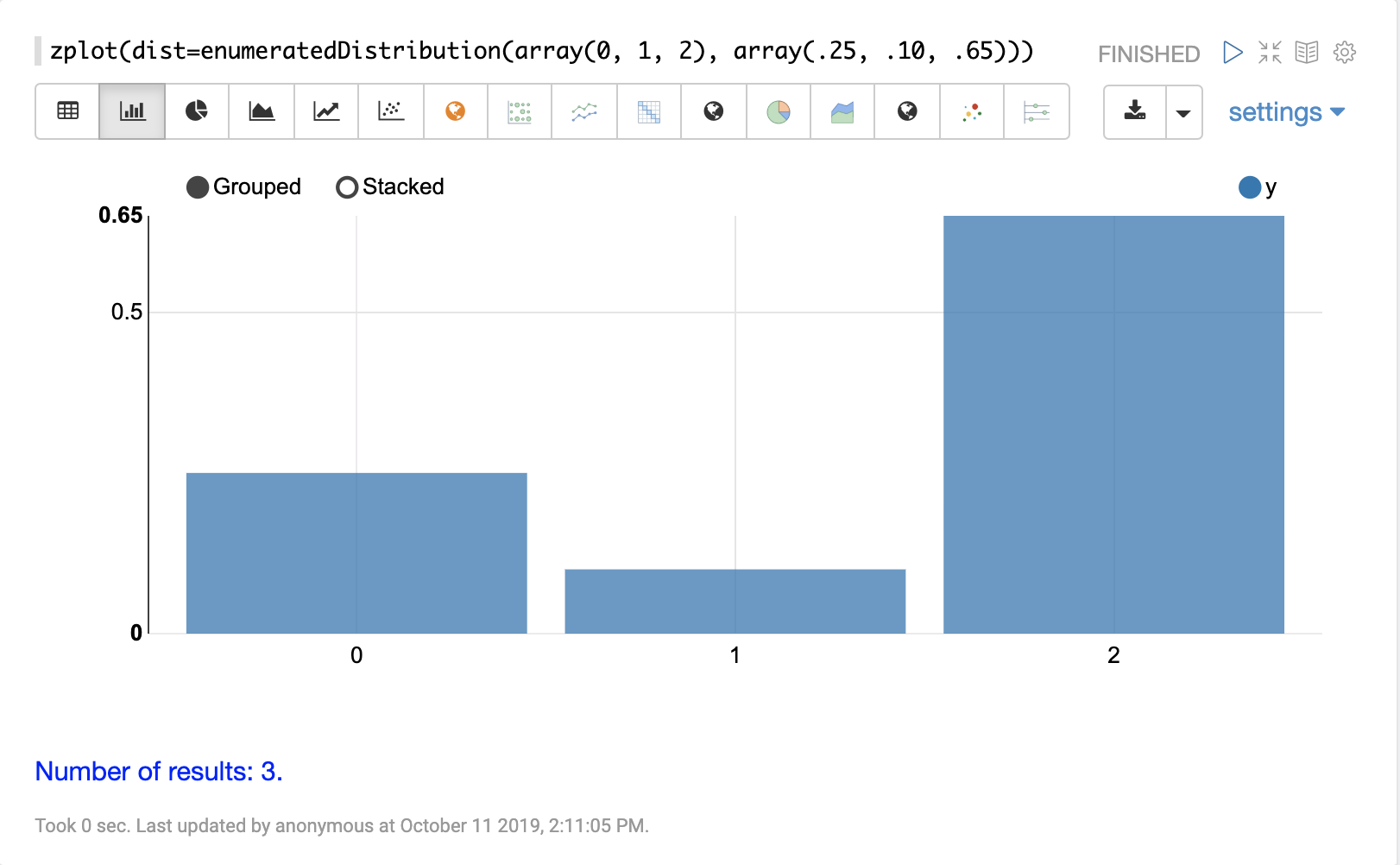
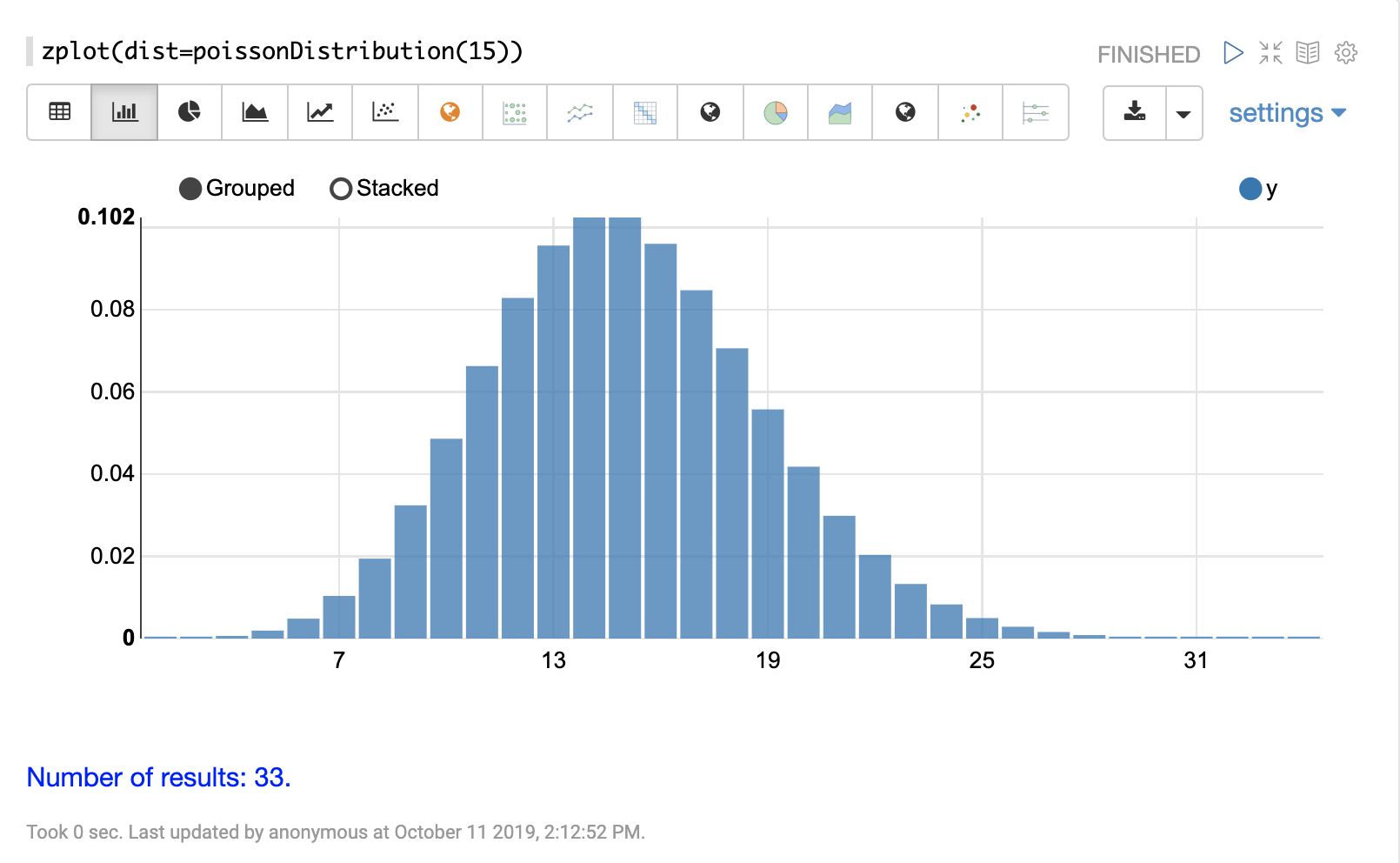
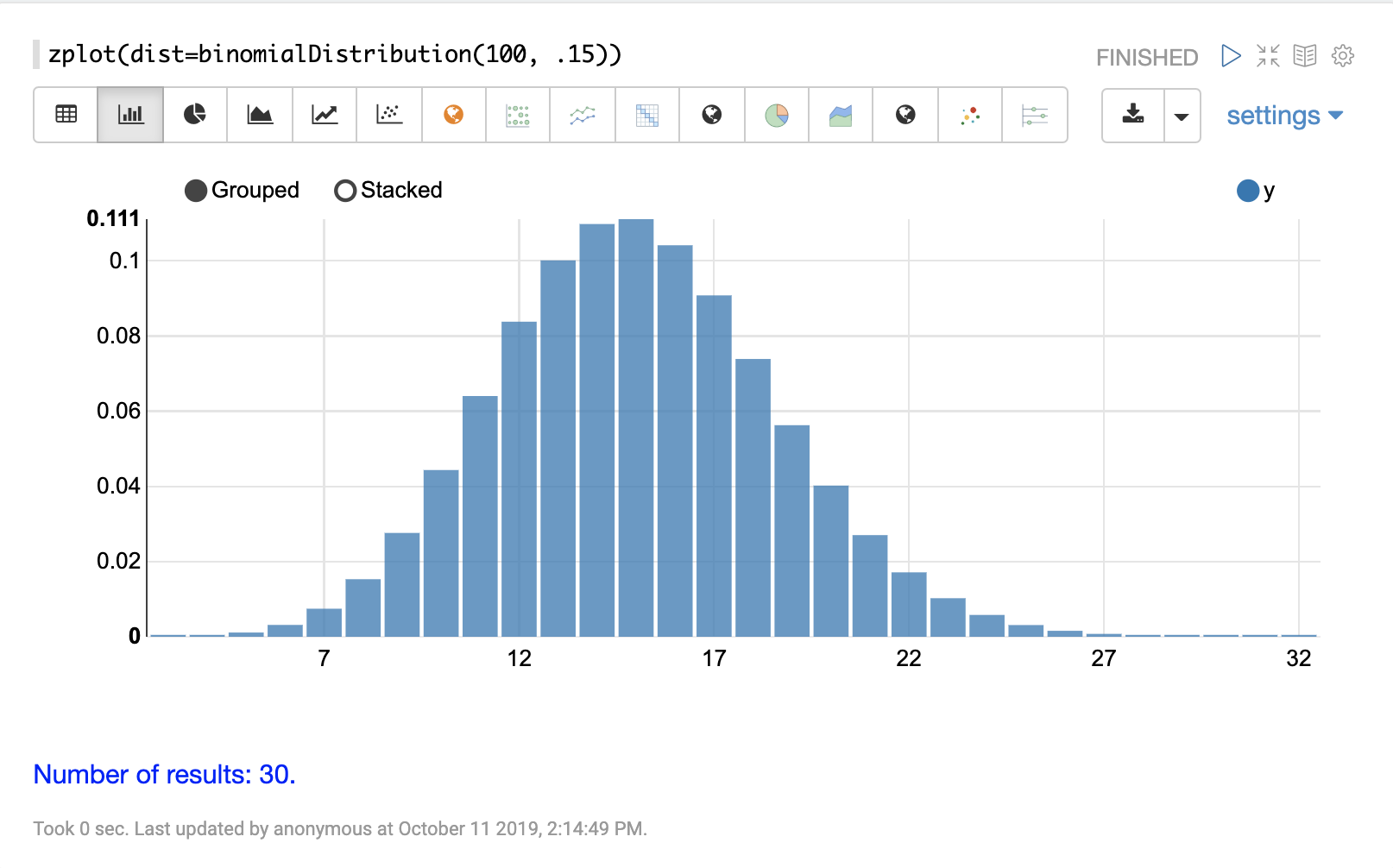
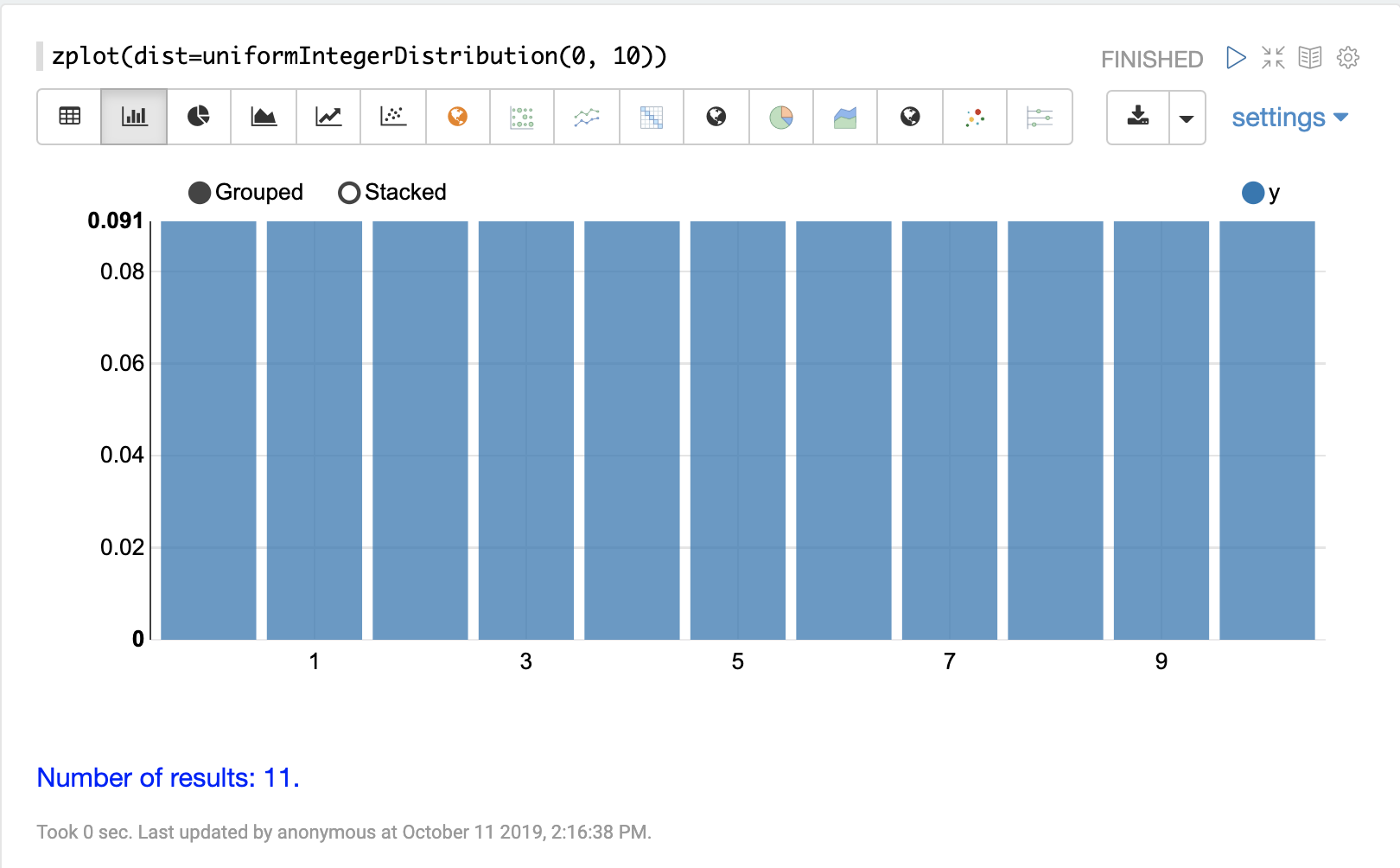
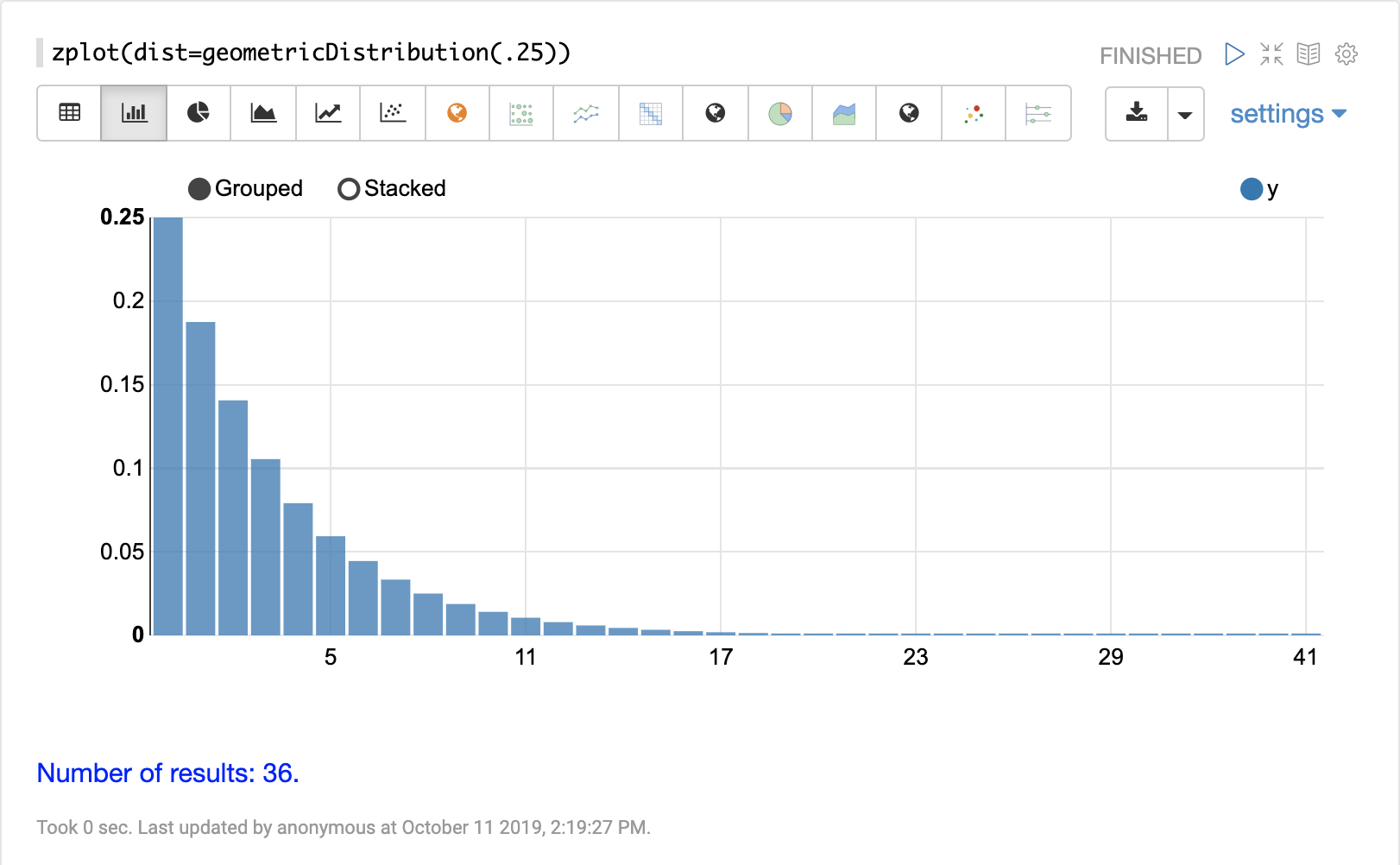
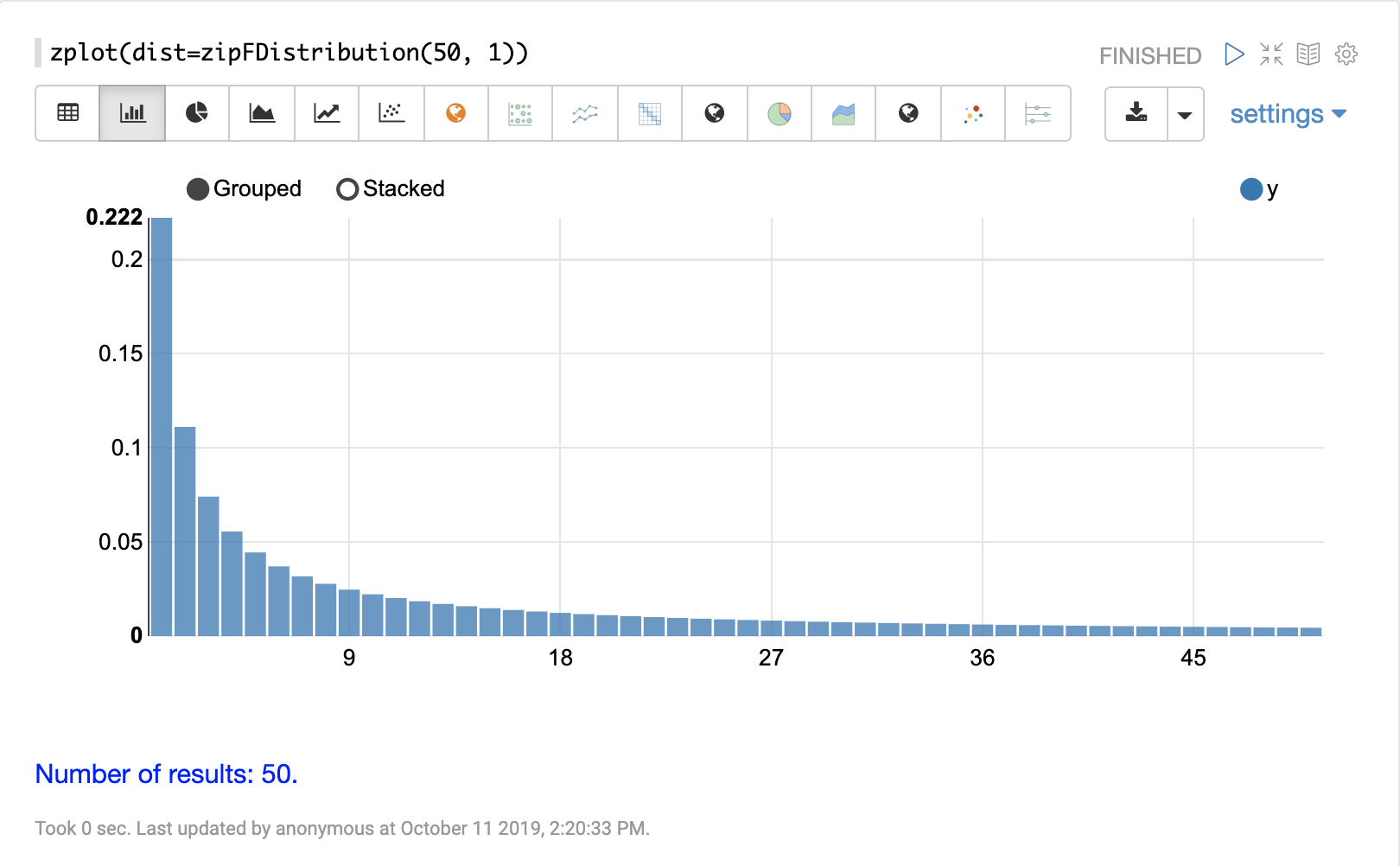
累积概率
cumulativeProbability 函数可以与所有概率分布一起使用,以计算在特定分布中遇到特定随机变量的累积概率。
以下是计算正态分布中随机变量累积概率的示例。
let(a=normalDistribution(10, 5),
b=cumulativeProbability(a, 12))在此示例中,创建了一个均值为 10,标准差为 5 的正态分布函数。然后计算此特定分布中值 12 的累积概率。
当此表达式发送到 /stream 处理程序时,它会响应
{
"result-set": {
"docs": [
{
"b": 0.6554217416103242
},
{
"EOF": true,
"RESPONSE_TIME": 0
}
]
}
}概率
所有概率分布都可以计算某个值范围内的概率。
在以下示例中,从日志集合中提取的文件大小样本创建了一个经验分布。然后计算文件大小在 40000 到 41000 之间的概率为 19%。
let(a=random(logs, q="*:*", fl="filesize_d", rows="50000"),
b=col(a, filesize_d),
c=empiricalDistribution(b, 100),
d=probability(c, 40000, 41000))当此表达式发送到 /stream 处理程序时,它会响应
{
"result-set": {
"docs": [
{
"d": 0.19006540560734791
},
{
"EOF": true,
"RESPONSE_TIME": 550
}
]
}
}离散概率
probability 函数可以与任何离散分布函数一起使用,以计算离散值的概率。
以下示例计算泊松分布中离散值的概率。
在该示例中,创建了一个均值为 100 的泊松分布函数。然后计算此特定分布中遇到离散值 101 的样本的概率。
let(a=poissonDistribution(100),
b=probability(a, 101))当此表达式发送到 /stream 处理程序时,它会响应
{
"result-set": {
"docs": [
{
"b": 0.039466333474403106
},
{
"EOF": true,
"RESPONSE_TIME": 0
}
]
}
}采样
所有概率分布都支持采样。 sample 函数从概率分布中返回一个或多个随机样本。
以下是从正态分布中抽取单个样本的示例。
let(a=normalDistribution(10, 5),
b=sample(a))当此表达式发送到 /stream 处理程序时,它会响应
{
"result-set": {
"docs": [
{
"b": 11.24578055004963
},
{
"EOF": true,
"RESPONSE_TIME": 0
}
]
}
}sample 函数还可以返回样本向量。样本向量可以可视化为散点图,以直观地了解基础分布。
第一个示例显示了均值为 0,标准差为 5 的正态分布的散点图。
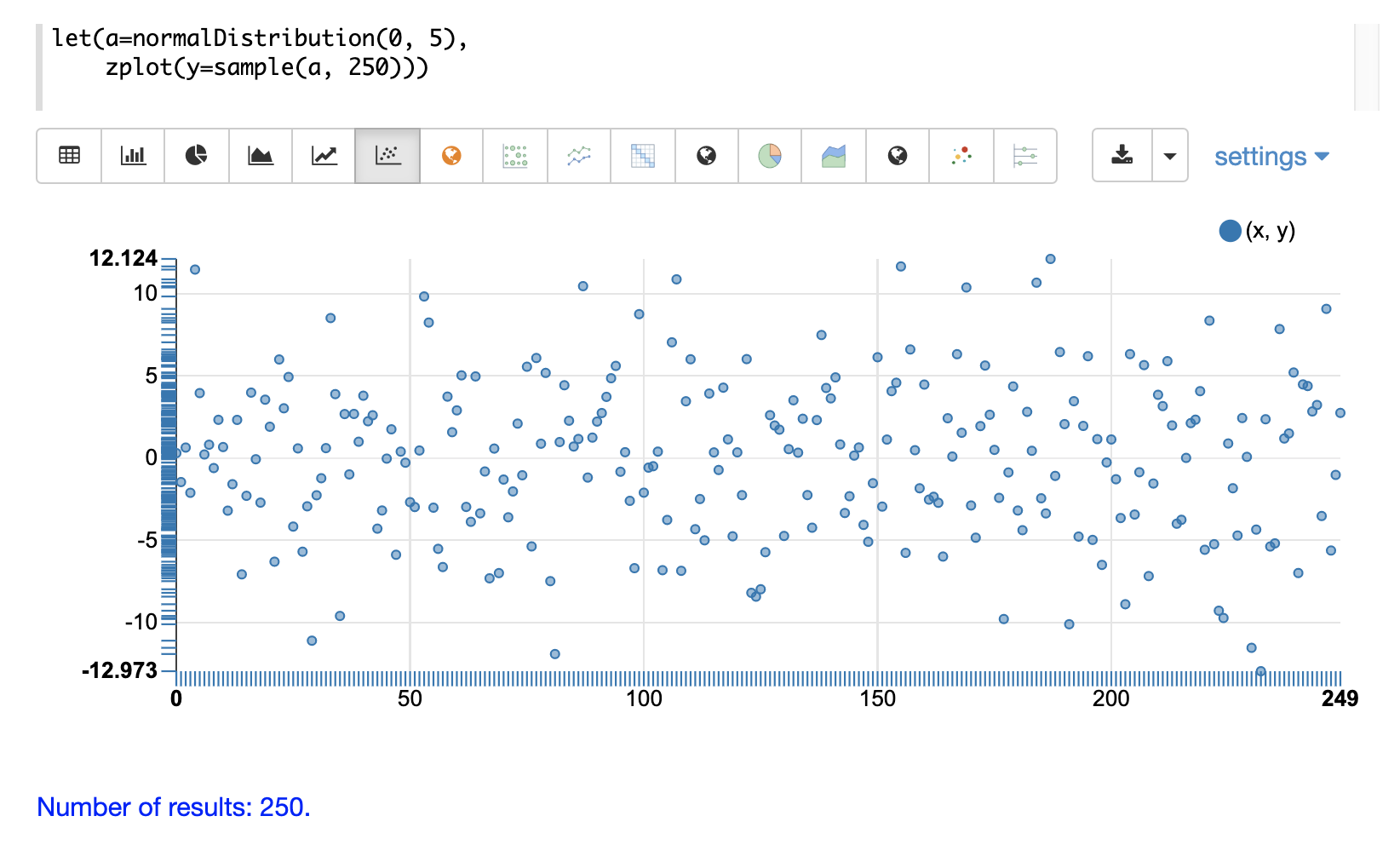
下一个示例显示了对样本向量应用升序排序的相同分布的散点图。
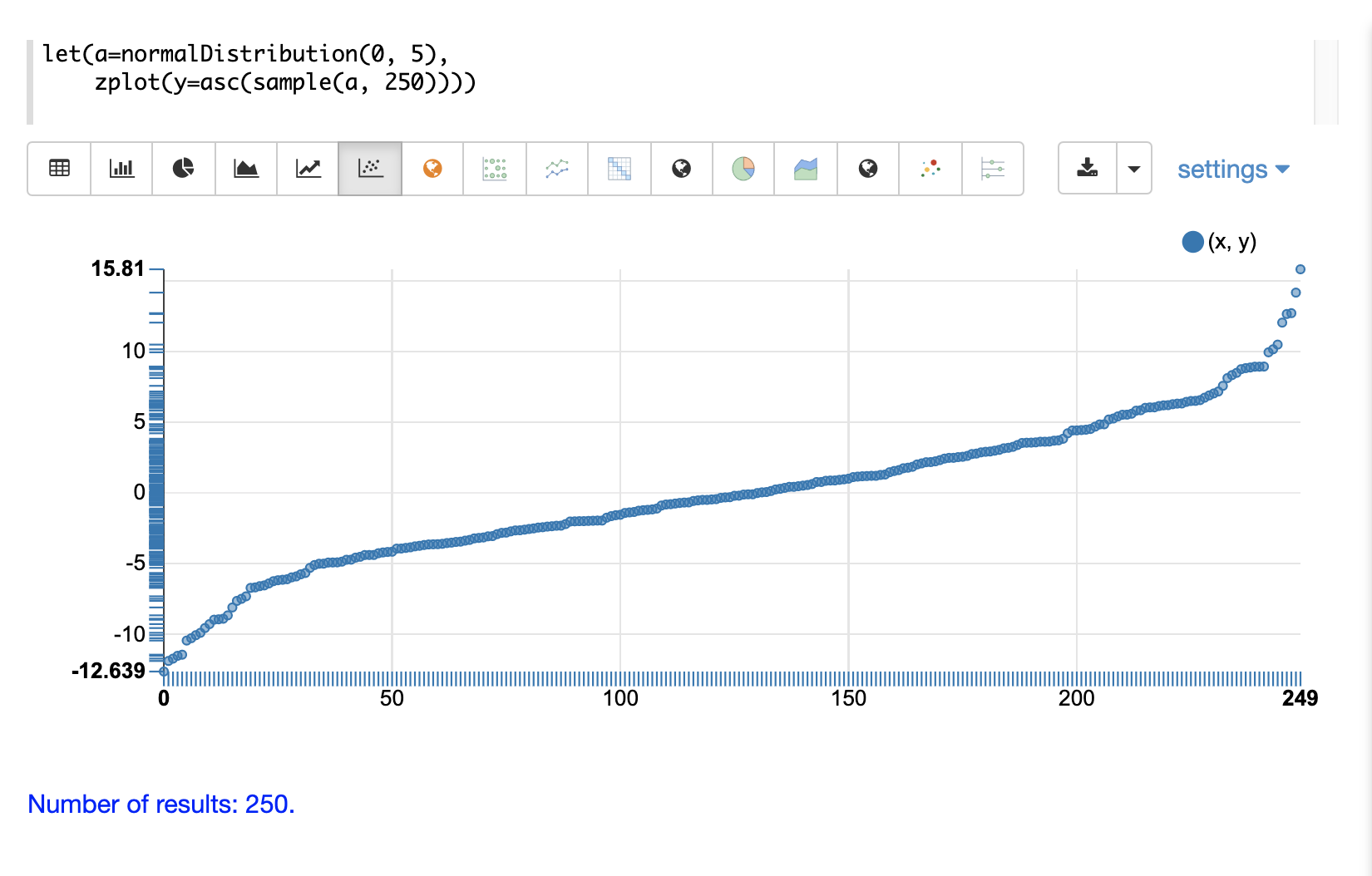
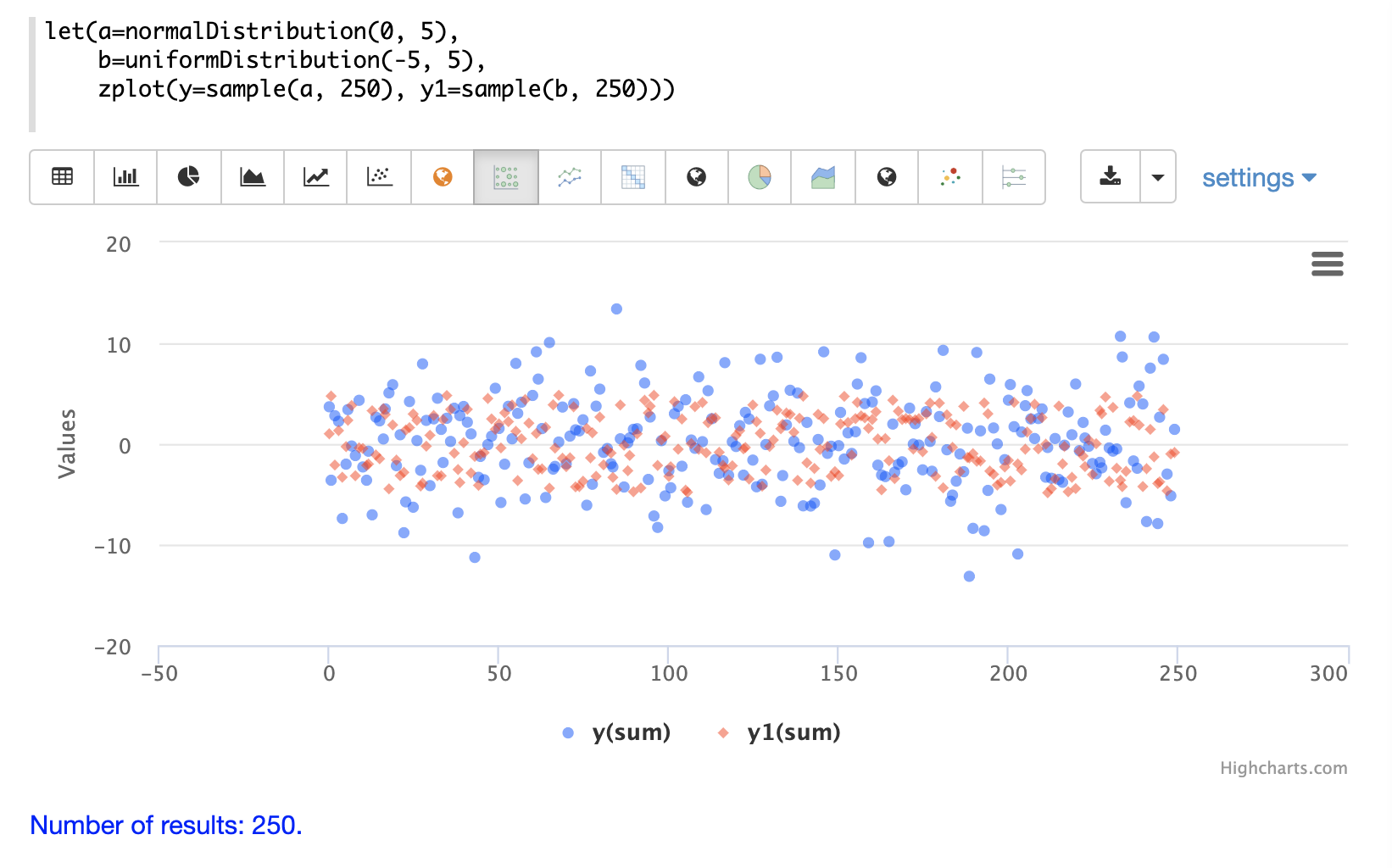
下一个示例显示了在同一散点图中叠加的两个不同分布。
多元正态分布
多元正态分布是单变量正态分布向更高维度的推广。
多元正态分布对两个或多个呈正态分布的随机变量进行建模。变量之间的关系由协方差矩阵定义。
采样
sample 函数可用于从多元正态分布中抽取样本,其方式与单变量正态分布非常相似。
不同之处在于,每个样本都将是一个数组,其中包含从每个基础正态分布中抽取的样本。如果抽取多个样本,则 sample 函数将返回一个矩阵,其中每一行包含一个样本。从长远来看,样本矩阵的列将符合用于参数化多元正态分布的协方差矩阵。
下面的示例演示如何从多元正态分布初始化和抽取样本。
在此示例中,从日志记录集合中选择了 5000 个随机样本。每个样本都包含字段 filesize_d 和 response_d。两个字段的值都符合正态分布。
然后将两个字段向量化。 filesize_d 向量存储在变量 b 中, response_d 变量存储在变量 c 中。
创建一个数组,其中包含两个向量化字段的均值。
然后将两个向量添加到转置的矩阵中。 这将创建一个观测矩阵,其中每一行包含 filesize_d 和 response_d 的一个观测值。然后,使用 cov 函数从观测矩阵的列创建协方差矩阵。协方差矩阵描述了 filesize_d 和 response_d 之间的协方差。
然后使用两个字段的均值数组和协方差矩阵调用 multivariateNormalDistribution 函数。多元正态分布的模型分配给变量 g。
最后,从多元正态分布中抽取五个样本。
let(a=random(logs, q="*:*", rows="5000", fl="filesize_d, response_d"),
b=col(a, filesize_d),
c=col(a, response_d),
d=array(mean(b), mean(c)),
e=transpose(matrix(b, c)),
f=cov(e),
g=multiVariateNormalDistribution(d, f),
h=sample(g, 5))样本以矩阵形式返回,每行代表一个样本。矩阵中有两列。第一列包含 filesize_d 的样本,第二列包含 response_d 的样本。从长远来看,列之间的协方差将符合用于实例化多元正态分布的协方差矩阵。
{
"result-set": {
"docs": [
{
"h": [
[
41974.85669321393,
779.4097049705296
],
[
42869.19876441414,
834.2599296790783
],
[
38556.30444839889,
720.3683470060988
],
[
37689.31290928216,
686.5549428100018
],
[
40564.74398214547,
769.9328090774
]
]
},
{
"EOF": true,
"RESPONSE_TIME": 162
}
]
}
}