其他查询解析器
除了主要的查询解析器外,还有一些其他的查询解析器,可以用来代替或与主要的解析器结合使用,以满足特定目的。
本节详细介绍了其他解析器,并提供了如何使用它们的示例。
这些解析器中的许多都以与本地参数相同的方式表示。
块连接查询解析器
块连接查询解析器与嵌套文档一起使用,以查询父文档和/或子文档。
这些解析器在块连接查询解析器一节中详细介绍。
布尔查询解析器
BoolQParser 创建一个 Lucene BooleanQuery,它是其他查询的布尔组合。子查询及其类型化的出现方式指示文档将如何匹配和评分。
参数
must-
可选
默认值:无
匹配文档中**必须**出现并对评分做出贡献的查询列表。
must_not-
可选
默认值:无
匹配文档中**必须不**出现的查询列表。
should-
可选
默认值:无
匹配文档中**应该**出现的查询列表。对于没有
must查询的 BooleanQuery,必须匹配一个或多个should查询,BooleanQuery 才能匹配。 filter-
可选
默认值:无
匹配文档中**必须**出现的查询列表。但是,与
must不同,过滤器查询的评分将被忽略。此外,这些查询缓存在过滤器缓存中。为了避免缓存,请添加cache=false作为本地参数,或向基础 Query DSL 对象添加"cache":"false"属性。 mm-
可选
默认值:
0必须匹配的可选子句的数量。默认情况下,匹配不需要可选子句(除非没有必需子句)。如果设置此参数,则需要指定数量的
should子句。如果未设置此参数,则关于布尔查询的常用规则在搜索时仍然适用 - 也就是说,包含无必需子句的布尔查询仍然必须匹配至少一个可选子句。 excludeTags-
可选
默认值:无
用于从上述参数中排除查询的逗号分隔标记列表。请参阅下面的解释。
示例
{!bool must=foo must=bar}{!bool filter=foo should=bar}{!bool should=foo should=bar should=qux mm=2}参数也可能是多值引用。上面的前一个示例等效于
q={!bool must=$ref}&ref=foo&ref=bar可以通过标记排除引用的查询。总的来说,这个想法类似于在分面中排除 fq。
q={!bool must=$ref excludeTags=t2}&ref={!tag=t1}foo&ref={!tag=t2}bar由于后面的查询通过 t2 排除,因此生成的查询等效于
q={!bool must=foo}提升查询解析器
BoostQParser 扩展了 QParserPlugin,并从输入值创建一个提升的查询。主要值是要“包装”和“提升”的任何查询 - 只有与该查询匹配的文档才会匹配此解析器生成的最终查询。参数 b 是一个函数,将针对与原始查询匹配的每个文档进行评估,并且该函数的结果将乘以该文档的最终评分。
提升查询解析器示例
创建一个查询 name:foo,该查询通过函数查询 log(popularity) 进行提升(评分相乘)
q={!boost b=log(popularity)}name:foo创建一个查询 name:foo,其评分乘以数字 price 字段的*倒数* - 通过降低最终评分有效地“降低”具有高 price 的文档的评分
// NOTE: we "add 1" to the denominator to prevent divide by zero
q={!boost b=div(1,add(1,price))}name:fooquery(…) 函数对于希望将与主查询匹配的每个文档的评分乘以该文档从另一个查询获得的评分的情况特别有用。
此示例使用本地参数变量创建一个用于 name:foo 的查询,该查询由独立指定的查询 category:electronics 的评分进行提升
q={!boost b=query($my_boost)}name:foo
my_boost=category:electronics折叠查询解析器
CollapsingQParser 实际上是一个后置过滤器,当结果集中不同组的数量很高时,它比 Solr 的标准方法提供更高效的字段折叠。
此解析器在将结果集转发到其余搜索组件之前,将结果集折叠为每组一个文档。因此,所有下游组件(分面、高亮等)都将使用折叠后的结果集。
有关使用 CollapsingQParser 的详细信息,请参阅折叠和展开结果部分。
复杂短语查询解析器
ComplexPhraseQParser 使用 Lucene 的 ComplexPhraseQueryParser 提供对短语查询中通配符、OR 等的支持。
在底层,此查询解析器利用 Span 查询组,例如 spanNear、spanOr 等,并且受限于该解析器系列的相同限制。
参数
inOrder-
可选
默认值:
true设置为
true可强制短语查询按指定顺序匹配词语。 df-
可选
默认值:无
默认搜索字段。
示例
{!complexphrase inOrder=true}name:"Jo* Smith"{!complexphrase inOrder=false}name:"(john jon jonathan~) peters*"混合了有序和无序的复杂短语查询
+_query_:"{!complexphrase inOrder=true}manu:\"a* c*\"" +_query_:"{!complexphrase inOrder=false df=name}\"bla* pla*\""复杂短语解析器限制
性能对与模式关联的唯一词语数量敏感。例如,搜索 "a*" 将为索引中以单个字母 'a' 开头的指定字段的所有词语形成一个大的 OR 子句(技术上是具有多个词语的 SpanOr)。将通配符限制为至少两个或最好三个字母作为前缀可能是明智的。允许非常短的前缀可能会导致返回太多低质量的文档。
请注意,它也支持前导通配符 "*a",但会带来相应的性能影响。通常建议在索引时分析中应用 ReversedWildcardFilterFactory。
查询设置和复杂短语解析器
由于上述查询扩展,此解析器可能会生成违反多个 solrconfig.xml 设置的查询。
特别相关的是 maxBooleanClauses 和 minPrefixLength,这是 Solr 提供的两个安全措施,旨在抑制资源密集型查询。
<maxBooleanClauses>4096</maxBooleanClauses>
<minPrefixLength>1</minPrefixLength>这两个属性在查询大小调整和预热部分中有更详细的描述。管理员在进行更改以支持“复杂短语”查询时应仔细考虑性能权衡。
复杂短语解析器中的停用词
不建议将停用词消除与此查询解析器一起使用。
假设我们将术语 the、up 和 to 添加到集合的 stopwords.txt 中,并在名为“features”的字段中索引包含文本“Stores up to 15,000 songs, 25,00 photos, or 150 yours of video” 的文档。
虽然下面的查询未使用此解析器
q=features:"Stores up to 15,000"但会返回该文档。下一个使用复杂短语查询解析器的查询(如下面的查询所示)
q=features:"sto* up to 15*"&defType=complexphrase不会返回该文档,因为 SpanNearQuery 没有类似于 PhraseQuery 的方式来很好地处理停用词。如果必须为您的用例删除停用词,请使用自定义过滤器工厂,或者可能使用自定义的同义词过滤器将给定的停用词简化为某些不可能的标记。
字段查询解析器
FieldQParser 扩展了 QParserPlugin,并从输入值创建字段查询,应用文本分析并在适当的情况下构造短语查询。参数 f 是要查询的字段。
示例
{!field f=myfield}Foo Bar此示例创建一个短语查询,其中 “foo” 后跟 “bar”(假设 myfield 的分析器是一个文本字段,其分析器按空格和转换为小写的术语进行拆分)。这通常等效于 Lucene 查询解析器表达式 myfield:"Foo Bar"。
过滤器查询解析器
语法为
q={!filters param=$fqs excludeTags=sample}field:text&
fqs=COLOR:Red&
fqs=SIZE:XL&
fqs={!tag=sample}BRAND:Foo
这等效于
q=+field:text +COLOR:Red +SIZE:XL
param 本地参数使用“$”语法引用一些查询,其中 excludeTags 可能会省略其中的一些查询。
函数查询解析器
FunctionQParser 扩展了 QParserPlugin,并从输入值创建函数查询。这只是在 Solr 中使用函数查询的一种方式;对于另一种更集成的方案,请参阅函数查询部分。
示例
{!func}log(foo)函数范围查询解析器
FunctionRangeQParser 扩展了 QParserPlugin,并创建基于函数的范围查询。这也被称为 frange,如下面的示例所示。
参数
l-
可选
默认值:无
下限。
u-
可选
默认值:无
上限。
incl-
可选
默认值:
true包括下限。
incu-
可选
默认值:
true包括上限。
示例
{!frange l=1000 u=50000}myfield fq={!frange l=0 u=2.2} sum(user_ranking,editor_ranking)这两个示例都通过声明字段或函数查询中找到的值范围来限制结果。在第二个示例中,我们正在进行求和计算,然后定义仅应将 0 到 2.2 之间的值返回给用户。
有关基于函数的范围查询的更多信息,请参阅 Yonik Seeley 的入门博客文章 Solr 1.4 中基于函数的范围。
图查询解析器
graph 查询解析器对从包装查询标识的一组起始根文档“可到达”的所有文档进行广度优先、循环感知的图遍历。
该图根据文档之间基于在查询中指定的 from 和 to 字段中找到的术语的链接来构建。
支持的字段类型是启用 docValues 的点字段或具有 indexed=true 或 docValues=true 的字符串字段。
对于 indexed=false 和 docValues=true 的字符串字段,请参阅 SortedDocValuesField.newSlowSetQuery() 的 javadocs 以了解其性能特征,因此对于大多数用例,indexed=true 将具有更好的性能。 |
图查询参数
to-
可选
默认值:
edge_ids要检查的匹配文档的字段名称,以识别图遍历的出边。
from-
可选
默认值:
node_id要检查的候选文档中的字段名称,以识别传入的图边。
traversalFilter-
可选
默认值:无
一个可选的查询,可用于限制遍历的文档范围。
maxDepth-
可选
默认值:
-1(无限制)整数,指定从初始查询开始,图的广度优先搜索应进行多深。
returnRoot-
可选
默认值:
true布尔值,指示是否应将与原始查询匹配的文档(以定义图的起点)包含在最终结果中。
returnOnlyLeaf-
可选
默认值:
false布尔值,指示是否应过滤查询结果,以便仅返回没有出边的文档。
useAutn-
可选
默认值:
false布尔值,指示是否应为广度优先搜索的每次迭代编译自动机,这对于某些图可能更快。
图查询示例
为了了解图解析器的工作原理,请考虑以下有向循环图,其中包含 8 个节点(A 到 H)和 9 条边(1 到 9)
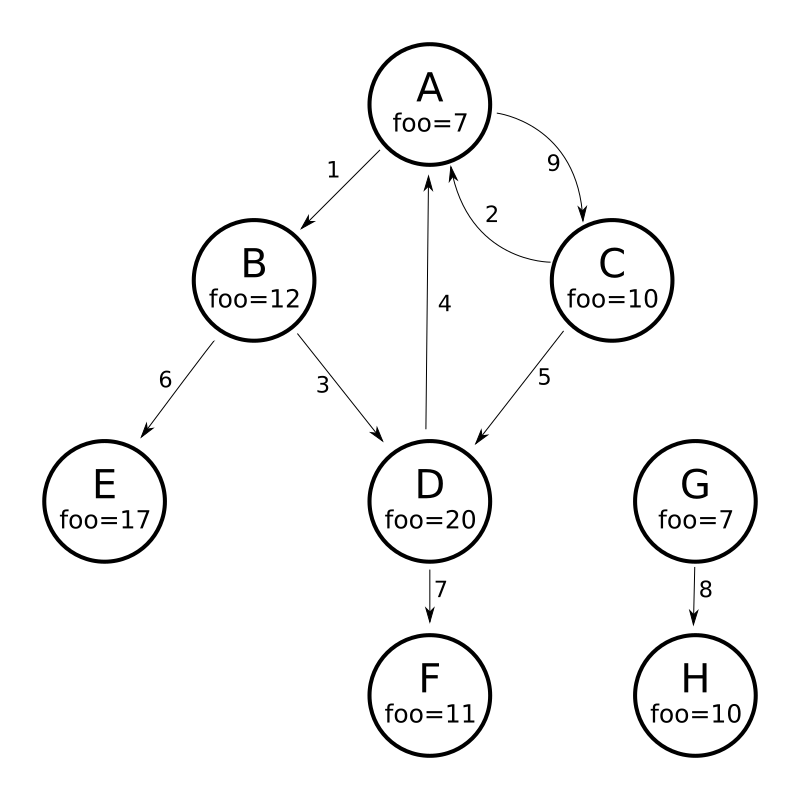
将此图建模为 Solr 文档的一种方法是为每个节点创建一个文档,其中多值字段标识每个节点的传入和出边
curl -H 'Content-Type: application/json' 'https://:8983/solr/my_graph/update?commit=true' --data-binary '[
{"id":"A","foo": 7, "out_edge":["1","9"], "in_edge":["4","2"] },
{"id":"B","foo": 12, "out_edge":["3","6"], "in_edge":["1"] },
{"id":"C","foo": 10, "out_edge":["5","2"], "in_edge":["9"] },
{"id":"D","foo": 20, "out_edge":["4","7"], "in_edge":["3","5"] },
{"id":"E","foo": 17, "out_edge":[], "in_edge":["6"] },
{"id":"F","foo": 11, "out_edge":[], "in_edge":["7"] },
{"id":"G","foo": 7, "out_edge":["8"], "in_edge":[] },
{"id":"H","foo": 10, "out_edge":[], "in_edge":["8"] }
]'使用上面显示的模型,以下查询演示了从节点 A 可到达的所有节点的简单遍历
https://:8983/solr/my_graph/query?fl=id&q={!graph+from=in_edge+to=out_edge}id:A"response":{"numFound":6,"start":0,"docs":[
{ "id":"A" },
{ "id":"B" },
{ "id":"C" },
{ "id":"D" },
{ "id":"E" },
{ "id":"F" } ]
}我们还可以使用 traversalFilter 将图遍历限制为仅包含 foo 字段中最大值为 15 的节点。在这种情况下,这意味着排除 D、E 和 F – F 的值为 foo=11,但由于遍历跳过了 D,因此它不可到达
https://:8983/solr/my_graph/query?fl=id&q={!graph+from=in_edge+to=out_edge+traversalFilter='foo:[*+TO+15]'}id:A...
"response":{"numFound":3,"start":0,"docs":[
{ "id":"A" },
{ "id":"B" },
{ "id":"C" } ]
}到目前为止显示的示例都使用单个文档("id:A")的查询作为图遍历的根节点,但可以使用任何查询来识别多个文档以用作根节点。下一个示例演示如何使用 maxDepth 参数查找距离 foo 字段中值小于或等于 10 的根节点最多一条边距离的所有节点
https://:8983/solr/my_graph/query?fl=id&q={!graph+from=in_edge+to=out_edge+maxDepth=1}foo:[*+TO+10]...
"response":{"numFound":6,"start":0,"docs":[
{ "id":"A" },
{ "id":"B" },
{ "id":"C" },
{ "id":"D" },
{ "id":"G" },
{ "id":"H" } ]
}简化模型
上述示例中使用的文档和字段建模明确枚举了每个节点的所有出边和入边,以帮助演示 “from” 和 “to” 参数的工作原理,并让您了解可以实现的功能。对于识别入边和出边的多个字段集,可以对许多独立的有向图进行建模,这些有向图包含集合中的某些或所有文档。
但在许多情况下,也可以大大简化所使用的模型。
例如,上面图中显示的同一图可以使用 Solr 文档进行建模,这些文档表示每个节点并且仅知道它们链接到的节点的 ID,而不知道任何有关传入链接的信息
curl -H 'Content-Type: application/json' 'https://:8983/solr/alt_graph/update?commit=true' --data-binary '[
{"id":"A","foo": 7, "out_edge":["B","C"] },
{"id":"B","foo": 12, "out_edge":["E","D"] },
{"id":"C","foo": 10, "out_edge":["A","D"] },
{"id":"D","foo": 20, "out_edge":["A","F"] },
{"id":"E","foo": 17, "out_edge":[] },
{"id":"F","foo": 11, "out_edge":[] },
{"id":"G","foo": 7, "out_edge":["H"] },
{"id":"H","foo": 10, "out_edge":[] }
]'使用此替代文档模型,仍然可以通过简单地更改 “from” 参数以将 “in_edge” 字段替换为 “id” 字段来执行上述所有相同的查询
https://:8983/solr/alt_graph/query?fl=id&q={!graph+from=id+to=out_edge+maxDepth=1}foo:[*+TO+10]...
"response":{"numFound":6,"start":0,"docs":[
{ "id":"A" },
{ "id":"B" },
{ "id":"C" },
{ "id":"D" },
{ "id":"G" },
{ "id":"H" } ]
}哈希范围查询解析器
哈希范围查询解析器将返回具有包含将哈希到特定范围的值的字段的文档。当使用 method=crossCollection 时,join 查询解析器会使用此解析器。哈希范围查询解析器为该查询解析器将操作的每个字段都有一个段缓存。
当使用哈希范围查询解析器指定最小/最大哈希范围和字段名称时,仅返回包含哈希到该范围内的字段值的文档。如果要查询非常大的结果集,可以查询不同的哈希范围,以在每个范围请求中返回一部分文档。
在跨集合连接的情况下,哈希范围查询解析器用于确保每个分片仅获取最终在该分片上的连接键集。
此查询解析器使用 MurmurHash3_x86_32。这与 Solr 中默认复合 ID 路由器的默认哈希相同。
Join 查询解析器
Join 查询解析器允许用户运行查询,以规范化文档之间的关系,类似于 SQL 样式的连接。
有关此查询解析器的详细信息,请参阅 Join 查询解析器 部分。
学习排序查询解析器
LTRQParserPlugin 是一个专用解析器,用于使用基于机器学习模型的更复杂的排名查询,对简单查询的顶部结果进行重新排名。
示例
{!ltr model=myModel reRankDocs=100}有关使用 LTRQParserPlugin 的详细信息,请参阅 学习排序 部分。
最大分数查询解析器
MaxScoreQParser 扩展了 LuceneQParser,但返回子句中的最大分数。 它通过将所有 SHOULD 子句包装在带有 tie=1.0 的 DisjunctionMaxQuery 中来实现此目的。任何 MUST 或 PROHIBITED 子句都按原样传递。 非布尔查询(例如,NumericRange)会回退到 LuceneQParser 解析器的行为。
示例
{!maxscore tie=0.01}C OR (D AND E)MinHash 查询解析器
MinHashQParser 为使用 MinHashFilterFactory 分析的字段构建查询。 查询测量查询字符串和 MinHash 字段之间的 Jaccard 相似度;如果需要,允许更快的近似匹配。 该解析器支持两种操作模式。 第一种模式,当 token 从文本通过正常分析生成时;第二种模式,当提供显式 token 时。
目前,查询返回的分数反映了匹配的顶级元素的数量,并且在 0 到 1 之间未标准化。
sim-
必需
默认值:无
最小相似度。 默认行为是查找任何大于零的相似度。 介于
0.0和1.0之间的数值。 tp-
可选
默认值:
1.0所需的真阳性率。 对于小于
1.0的值,可以使用优化且更快的带状查询。 带状行为取决于请求的sim和tp的值。 field-
可选
默认值:无
索引 MinHash 值的字段。 此字段通常用于分析提供给查询解析器的文本。 它也用于查询字段。
sep-
可选
默认值: " " (空字符串)
分隔符字符串。 如果提供了非空分隔符字符串,则将查询字符串解释为由分隔符字符串分隔的预分析值的列表。 在这种情况下,不对字符串执行其他分析:token 按原样使用。
analyzer_field-
可选
默认值:无
此参数可用于定义文本的分析方式,与查询字段不同。 当使用预分析字符串
field来存储 MinHash 值时,它用于分析查询文本。 请参阅下面的示例。
此查询解析器注册的名称为 min_hash。
带分析字段的示例
典型分析
<fieldType name="text_min_hash" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.ICUTokenizerFactory"/>
<filter class="solr.ICUFoldingFilterFactory"/>
<filter class="solr.ShingleFilterFactory" minShingleSize="5" outputUnigrams="false" outputUnigramsIfNoShingles="false" maxShingleSize="5" tokenSeparator=" "/>
<filter class="org.apache.lucene.analysis.minhash.MinHashFilterFactory" bucketCount="512" hashSetSize="1" hashCount="1"/>
</analyzer>
</fieldType>
...
<field name="min_hash_analysed" type="text_min_hash" multiValued="false" indexed="true" stored="false" />在此处,输入文本按空格分割,token 被标准化,生成的 token 流被组装成所有 5 个单词的 shingles 的流,然后进行哈希处理。 保留每个 512 个桶中最低的哈希值,并生成为输出 token。
对此字段的查询需要生成至少一个 shingle,因此需要 5 个不同的 token。
示例查询
{!min_hash field="min_hash_analysed"}At least five or more tokens
{!min_hash field="min_hash_analysed" sim="0.5"}At least five or more tokens
{!min_hash field="min_hash_analysed" sim="0.5" tp="0.5"}At least five or more tokens带预分析字段的示例
此处,MinHash 是预先计算的,最有可能使用如下所示的 Lucene 内联分析。 从模式中获取分析器会更谨慎。
ICUTokenizerFactory factory = new ICUTokenizerFactory(Collections.EMPTY_MAP);
factory.inform(null);
Tokenizer tokenizer = factory.create();
tokenizer.setReader(new StringReader(text));
ICUFoldingFilterFactory filter = new ICUFoldingFilterFactory(Collections.EMPTY_MAP);
TokenStream ts = filter.create(tokenizer);
HashMap<String, String> args = new HashMap<>();
args.put("minShingleSize", "5");
args.put("outputUnigrams", "false");
args.put("outputUnigramsIfNoShingles", "false");
args.put("maxShingleSize", "5");
args.put("tokenSeparator", " ");
ShingleFilterFactory sff = new ShingleFilterFactory(args);
ts = sff.create(ts);
HashMap<String, String> args2 = new HashMap<>();
args2.put("bucketCount", "512");
args2.put("hashSetSize", "1");
args2.put("hashCount", "1");
MinHashFilterFactory mhff = new MinHashFilterFactory(args2);
ts = mhff.create(ts);
CharTermAttribute termAttribute = ts.getAttribute(CharTermAttribute.class);
ts.reset();
while (ts.incrementToken())
{
char[] buff = termAttribute.buffer();
...
}
ts.end();该模式将只定义一个多值字符串值和一个可选字段,用于在分析时使用 - 类似于上面。
<field name="min_hash_string" type="strings" multiValued="true" indexed="true" stored="true"/>
<!-- Optional -->
<field name="min_hash_analysed" type="text_min_hash" multiValued="false" indexed="true" stored="false"/>
<fieldType name="strings" class="solr.StrField" sortMissingLast="true" multiValued="true"/>
<!-- Optional -->
<fieldType name="text_min_hash" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.ICUTokenizerFactory"/>
<filter class="solr.ICUFoldingFilterFactory"/>
<filter class="solr.ShingleFilterFactory" minShingleSize="5" outputUnigrams="false" outputUnigramsIfNoShingles="false" maxShingleSize="5" tokenSeparator=" "/>
<filter class="org.apache.lucene.analysis.minhash.MinHashFilterFactory" bucketCount="512" hashSetSize="1" hashCount="1"/>
</analyzer>
</fieldType>示例查询
{!min_hash field="min_hash_string" sep=","}HASH1,HASH2,HASH3
{!min_hash field="min_hash_string" sim="0.9" analyzer_field="min_hash_analysed"}Lets hope the config and code for analysis are in sync也可以使用已知的哈希值来查询分析的字段(与上述相反)。
{!min_hash field="min_hash_analysed" analyzer_field="min_hash_string" sep=","}HASH1,HASH2,HASH3预分析字段意味着可以按文档恢复哈希值,而不是重新哈希。 返回 minhash 存储字段的初始查询阶段之后,可以跟一个 min_hash 查询以查找相似的文档。
带状查询
在上述配置的情况下,查询解析器的默认行为是生成一个布尔查询,并将 512 个恒定分数项查询 OR 在一起:每个哈希一个。 在这种情况下,如果一个哈希匹配,则生成分数为 1,如果所有哈希都匹配,则生成分数为 512。
带状查询混合了合取和析取。 我们可以有 256 个带,每个带都有两个查询 AND 在一起,128 个带有 4 个哈希 AND 在一起,等等。 随着带数的减少,查询性能提高,但我们可能会错过一些匹配项。 在速度和准确性之间存在权衡。 如果有 64 个带,则分数将从 0 到 64(OR 在一起的带数)不等。
给定所需的相似度和可接受的真阳性率,查询解析器会计算合适的带大小[1]。 它找到满足条件的最小带数
如果没有足够的哈希值来填充查询的最后一个带,则它会包裹到开头。
进一步阅读
有关一般介绍,请参阅“大规模数据集挖掘”[1]。
对于大约 1500 个单词的文档,预计索引大小开销约为 10%;您的里程可能会有所不同。 预计 512 个哈希值可以很好地表示约 2500 个单词。
在最初的论文[2]中提出了使用一组 MinHash 值,但提供了 Jaccard 相似度的有偏差估计。 在某些情况下,这种偏差可能是件好事。 同样,旋转和短文档也是如此。 该实现源自后来的工作中提出的无偏方法[3]。
[1] Leskovec, Jure; Rajaraman, Anand & Ullman, Jeffrey D. "Mining of Massive Datasets", Cambridge University Press; 第 2 版 (2014 年 12 月 29 日), 第 3 章, ISBN: 9781107077232。
[2] Broder, Andrei Z. (1997), "关于文档的相似性和包含", 序列的压缩和复杂性:会议记录,意大利萨莱诺阿马尔菲海岸波西塔诺,1997 年 6 月 11 日至 13 日 (PDF), IEEE, pp. 21–29, doi:10.1109/SEQUEN.1997.666900。
[3] Shrivastava, Anshumali & Li, Ping (2014), "一种排列哈希的改进密度化", 第 30 届人工智能不确定性会议 (UAI),加拿大魁北克市,2014 年 7 月 23 日至 27 日, AUAI, pp. 225-234, http://www.auai.org/uai2014/proceedings/individuals/225.pdf
更像此查询解析器
MLTQParser 允许检索与给定文档相似的文档。 它使用 Lucene 现有的 MoreLikeThis 逻辑,并且还可以在 SolrCloud 模式下工作。 有关如何使用此查询解析器的信息,请参阅有关 MoreLikeThis 的文档,请参阅 MoreLikeThis 查询解析器 部分。
嵌套查询解析器
NestedParser 扩展了 QParserPlugin 并创建了一个嵌套查询,该查询能够通过本地参数重新定义其类型。 这对于在配置中指定默认值并允许客户端间接引用它们很有用。
示例
{!query defType=func v=$q1}如果 q1 参数是 price,则该查询将是对价格字段的函数查询。 如果 q1 参数是 \{!lucene}inStock:true}},则从与 inStock=true 的文档匹配的 Lucene 语法字符串创建一个项查询。 这些参数将在 solrconfig.xml 的 defaults 部分中定义。
<lst name="defaults">
<str name="q1">{!lucene}inStock:true</str>
</lst>有关嵌套查询可能性的更多信息,请参阅 Yonik Seeley 的博客文章 Solr 中的嵌套查询。
有效负载查询解析器
这些查询解析器利用在索引期间在项上编码的有效负载。 可以使用 DelimitedPayloadTokenFilter 或 NumericPayloadTokenFilter 在项上编码有效负载。
有效负载分数解析器
PayloadScoreQParser 将每个匹配项的数值(整数或浮点数)有效负载合并到分数中。 从字段类型的查询分析中解析主查询,根据下面 operator 参数的值解析为 SpanQuery。
此解析器接受以下参数
f-
必需
默认值:无
要使用的字段。
func-
必需
默认值:无
有效负载函数。 选项为:
min、max、average或sum。 operator-
可选
默认值:无
搜索运算符。 选项为: *
or将生成SpanTermQuery或SpanOrQuery,具体取决于发出的 token 的数量。 *phrase将生成SpanTermQuery或有序的零斜率SpanNearQuery,具体取决于发出了多少个 token。 includeSpanScore-
可选
默认值:
false如果为
true,则将计算出的有效负载因子乘以原始查询的分数。 如果为false,则计算出的有效负载因子即为分数。
示例
{!payload_score f=my_field_dpf v=some_term func=max}{!payload_score f=payload_field func=sum operator=or}A B C有效负载检查解析器
PayloadCheckQParser 仅在匹配的词项也与有效载荷具有指定关系时才匹配。默认关系是相等,但也可以执行不等式匹配。对于这两个解析器,主查询都直接从字段类型的查询分析中解析为 SpanQuery。生成的 SpanQuery 将是 SpanTermQuery 或有序的零斜率 SpanNearQuery,具体取决于发出的标记数量。最终效果是,主查询的操作方式始终类似于标准 Lucene 解析器中的短语查询(因此忽略 q.op 的任何值)。
当字段分析应用于查询时,如果它更改了标记的数量,则最终的标记数量必须与 payloads 参数中提供的有效载荷数量相匹配。如果查询标记的数量与此查询提供的有效载荷值的数量不匹配,则查询将不会匹配。 |
此解析器接受以下参数
f-
必需
默认值:无
要使用的字段。
payloads-
必需
默认值:无
要与文档中匹配标记中的有效载荷进行比较的以空格分隔的有效载荷列表。每个指定的有效载荷都将使用从字段类型确定的编码器进行编码,然后再进行匹配。整数、浮点数和标识(字符串)编码都支持,其含义与
DelimitedPayloadTokenFilter相同。 op-
可选
默认值:
eq应用于有效载荷检查的不等式运算。所有操作都要求从查询分析中导出的连续标记与文档中的连续标记匹配,并且文档标记上的有效载荷必须: *
eq:等于指定的有效载荷 *gt:大于指定的有效载荷 *lt:小于指定的有效载荷 *gte:大于或等于指定的有效载荷 *lte:小于或等于指定的有效载荷
示例
查找所有包含短语“searching stuff”的文档,其中“searching”的有效载荷为“VERB”,“stuff”的有效载荷为“NOUN”
{!payload_check f=words_dps payloads="VERB NOUN"}searching stuff查找所有包含“foo”的文档,其中“foo”的有效载荷值大于或等于 0.75
{!payload_check f=words_dpf payloads="0.75" op="gte"}foo查找所有包含短语“foo bar”的文档,其中词项“foo”的有效载荷大于 9,“bar”的有效载荷大于 5
{!payload_check f=words_dpi payloads="9 5" op="gt"}foo bar
前缀查询解析器
PrefixQParser 通过从输入值创建前缀查询来扩展 QParserPlugin。目前,没有对创建此前缀查询进行分析或值转换。
参数是 f,即字段。前缀声明后的字符串被视为通配符查询。
示例
{!prefix f=myfield}foo这通常等效于 Lucene 查询解析器表达式 myfield:foo*。
原始查询解析器
RawQParser 通过从输入值创建词项查询来扩展 QParserPlugin,而无需任何文本分析或转换。这在调试时或从词项组件返回原始词项时非常有用(这不是默认设置)。
唯一的参数是 f,它定义要搜索的字段。
示例
{!raw f=myfield}Foo Bar此示例构造查询:TermQuery(Term("myfield","Foo Bar"))。
为了方便地构建过滤器以进行分面深入分析,建议使用 TermQParserPlugin。
为了对包括文本字段在内的所有字段进行完整分析,您可能需要使用 FieldQParserPlugin。
排名查询解析器
RankQParserPlugin 是 FunctionQParser 的排名相关功能的更快实现,并且可以与 RankFields 类型的专用字段一起使用。
它允许如下查询
https://:8983/solr/techproducts?q=memory _query_:{!rank f='pagerank', function='log' scalingFactor='1.2'}重新排名查询解析器
ReRankQParserPlugin 是一种特殊用途的解析器,用于使用更复杂的排名查询对简单查询的顶部结果进行重新排名。
有关使用 ReRankQParserPlugin 的详细信息,请参阅查询重新排名部分。
简单查询解析器
Solr 中的简单查询解析器基于 Lucene 的 SimpleQueryParser。此查询解析器旨在允许用户以他们想要的任何方式输入查询,并且它将尽力解释查询并返回结果。
此解析器采用以下参数
q.operators-
可选
默认值:请参阅描述
要启用的解析运算符的名称的逗号分隔列表。默认情况下,所有操作都已启用,并且可以使用此参数通过从列表中排除特定运算符来有效地禁用它们。使用此参数传递空字符串将禁用所有运算符。
名称 运算符 描述 示例查询 AND+指定 AND
token1+token2OR|指定 OR
token1|token2NOT-指定 NOT
-token3PREFIX*指定前缀查询
term*PHRASE"创建短语
"term1 term2"PRECEDENCE( )指定优先级;括号内的标记将首先分析。否则,正常顺序是从左到右。
token1 + (token2 | token3)ESCAPE\将其放在运算符前面以按字面意思匹配它们
C+\+WHITESPACE空格或
[\r\t\n]在空格上分隔标记。如果未启用,则在分析之前不会执行空格拆分 – 通常是最理想的。
不拆分空格是此解析器的独特功能,可使多词同义词起作用。但是,它可能实际上不会起作用,除非将同义词配置为规范化而不是扩展到所有与给定同义词匹配的项。这种配置需要在索引时和查询时都规范化同义词。Solr 的分析屏幕可以在这里提供帮助。
term1 term2FUZZY~~N在词项末尾,指定模糊查询。
“N”是可选的,可以是“1”或“2”(默认值)
term~1NEAR~N在短语末尾,指定 NEAR 查询
"term1 term2"~5 q.op-
可选
默认值:
OR定义用户未定义时要使用的默认运算符。允许的值为
AND和OR。如果未指定,则使用OR。 qf-
可选
默认值:无
构建查询时要使用的查询字段和提升的列表。
df-
可选
默认值:无
如果 Schema 中未定义默认字段,则定义默认字段;如果已定义默认字段,则覆盖默认字段。
任何语法错误都会被忽略,查询解析器将尽力解释查询。但是,在某些情况下,这可能会导致奇怪的结果。
空间查询解析器
Solr 中有两个空间 QParser:geofilt 和 bbox。但是还有其他方法可以进行空间查询:使用带有距离函数的 frange 解析器,使用具有范围语法的标准(lucene)查询解析器来选择矩形的角,或者使用 RPT 和 BBoxField,您可以使用标准查询解析器,但在引号内使用特殊语法,该语法允许您选择空间谓词。
所有这些选项都在 空间搜索部分中进行了进一步说明。
环绕查询解析器
SurroundQParser 启用环绕查询语法,该语法提供邻近搜索功能。有两个位置运算符:w 创建一个有序跨度查询,n 创建一个无序跨度查询。这两个运算符都采用一个数值来指示两个词项之间的距离。默认值为 1,最大值为 99。
请注意,查询字符串不会以任何方式进行分析。
示例
{!surround} 3w(foo, bar)此示例查找文档,其中词项“foo”和“bar”彼此之间的距离不超过 3 个词项(即它们之间不超过 2 个词项)。
此查询解析器还将接受布尔运算符(AND、OR 和 NOT,大小写均可)、通配符、用于短语搜索的引号和提升。w 和 n 运算符也可以用大写或小写形式表示。
非一元运算符(除 NOT 之外的所有运算符)支持中缀 (a AND b AND c) 和前缀 AND(a, b, c) 表示法。
切换查询解析器
SwitchQParser 是一个 QParserPlugin,它的作用类似于“switch”或“case”语句。
主要输入字符串被修剪,然后添加 case. 前缀,用作查找解析器本地参数中的“switch case”的键。如果找到匹配的本地参数,则将结果参数值解析为子查询,并作为解析结果返回。
可以将 case 本地参数可选地指定为与缺少(或空白)输入字符串匹配的 switch case。可以将 default 本地参数可选地指定为默认情况,以便在输入字符串与任何其他 switch case 本地参数不匹配时使用。如果未指定 default,则任何与 switch case 本地参数不匹配的输入都将导致语法错误。
在下面的示例中,每个查询的结果都是“XXX”
{!switch case.foo=XXX case.bar=zzz case.yak=qqq}foo} 和 bar 之间的额外空格会被自动修剪。{!switch case.foo=qqq case.bar=XXX case.yak=zzz} bar{!switch case.foo=qqq case.bar=zzz default=XXX}asdfcase 的值。{!switch case=XXX case.bar=zzz case.yak=qqq}此解析器的实际用途是在 SearchHandler 的配置中指定 appends 过滤器查询 (fq) 参数,以便为使用自定义参数名称的客户端提供一组固定的过滤器选项。
使用下面的示例配置,客户端可以选择指定自定义参数 in_stock 和 shipping 来覆盖默认的筛选行为,但仅限于特定的合法值集(shipping=any|free,in_stock=yes|no|all)。
<requestHandler name="/select" class="solr.SearchHandler">
<lst name="defaults">
<str name="in_stock">yes</str>
<str name="shipping">any</str>
</lst>
<lst name="appends">
<str name="fq">{!switch case.all='*:*'
case.yes='inStock:true'
case.no='inStock:false'
v=$in_stock}</str>
<str name="fq">{!switch case.any='*:*'
case.free='shipping_cost:0.0'
v=$shipping}</str>
</lst>
</requestHandler>词项查询解析器
TermsQParser 的功能类似于词项查询解析器,但接受多个以逗号分隔的值,并返回与任何指定值匹配的文档。
这对于从分面或词项组件返回的外部可读词项生成过滤器查询非常有用,并且在某些情况下可能比使用标准查询解析器生成布尔查询更有效,因为默认实现 method 避免了评分。
此查询解析器采用以下参数
f-
必需
默认值:无
要在其上搜索的字段。
separator-
可选
默认值:
,(逗号)解析输入时要使用的分隔符。如果设置为“ ”(单个空格),则将从输入词项中修剪额外的空格。
method-
可选
默认值:
termsFilter确定 Solr 应使用哪种查询实现。
选项仅限于:
termsFilter、booleanQuery、automaton、docValuesTermsFilterPerSegment、docValuesTermsFilterTopLevel或docValuesTermsFilter。每个实现都有其自身的性能特征,建议用户进行实验以确定哪个实现最适合其用例。下面给出了启发式方法。
booleanQuery创建一个表示请求的BooleanQuery。随索引大小扩展良好,但随要搜索的词项数量扩展不佳。termsFilter使用BooleanQuery或TermInSetQuery,具体取决于词项的数量。随索引大小扩展良好,但仅适度地随查询词项的数量扩展。docValuesTermsFilter只能用于具有 docValues 数据的字段。cache参数默认为 false。它通过查询词的数量作为粗略的启发式方法,在docValuesTermsFilterTopLevel和docValuesTermsFilterPerSegment方法之间进行选择。用户通常应该使用此方法,而不是直接使用docValuesTermsFilterTopLevel或docValuesTermsFilterPerSegment,除非他们已经进行了性能测试,以验证在所有大小的查询上其中一种方法的性能。根据所选的实现,此方法可能依赖于每次提交后延迟填充的昂贵的数据结构。如果您频繁提交,并且您的用例可以容忍静态预热查询,请考虑在solrconfig.xml中添加一个,以便此工作作为提交本身的一部分完成,而不是直接附加到用户请求。docValuesTermsFilterTopLevel只能用于具有 docValues 数据的字段。cache参数默认为 false。它使用顶级的 docValues 数据结构来查找结果。随着查询词数量的增加(超过几百个),这些数据结构效率更高。但它们构建的成本也很高,需要在每次提交后延迟填充,这会导致每次提交后的第一次查询出现有时明显的减速。如果您频繁提交,并且您的用例可以容忍静态预热查询,请考虑在solrconfig.xml中添加一个,以便此工作作为提交本身的一部分完成,而不是直接附加到用户请求。docValuesTermsFilterPerSegment只能用于具有 docValues 数据的字段。cache参数默认为 false。对于少量到中等数量(约 500 个)的查询词,它比“顶层”替代方案更有效,并且不会在提交后立即进行查询时出现减速(如docValuesTermsFilterTopLevel一样 - 请参见上文)。但是,对于非常大量的查询词,其性能较低。automaton创建一个AutomatonQuery,它表示请求,其中每个词形成一个联合。它在索引大小上表现良好,并且在查询词的数量上表现适中。
示例
{!terms f=tags}software,apache,solr,lucene{!terms f=categoryId method=booleanQuery separator=" "}8 6 7 5309XML 查询解析器
XmlQParserPlugin 扩展了 QParserPlugin,并支持从 XML 创建查询。示例:
| 参数 | 值 |
|---|---|
defType |
|
q |
|
XmlQParser 实现使用 SolrCoreParser 类,该类扩展了 Lucene 的 CoreParser 类。XML 元素被映射到 QueryBuilder 类,如下所示:
| XML 元素 | QueryBuilder 类 |
|---|---|
<BooleanQuery> |
|
<BoostingTermQuery> |
|
<ConstantScoreQuery> |
|
<DisjunctionMaxQuery> |
|
<MatchAllDocsQuery> |
|
<RangeQuery> |
|
<SpanFirst> |
|
<SpanPositionRange> |
|
<SpanNear> |
|
<SpanNot> |
|
<SpanOr> |
|
<SpanOrTerms> |
|
<SpanTerm> |
|
<TermQuery> |
|
<TermsQuery> |
|
<UserQuery> |
|
<LegacyNumericRangeQuery> |
LegacyNumericRangeQuery(Builder) 已弃用 |
自定义 XML 查询解析器
您可以为其他 XML 元素配置自己的自定义查询构建器。自定义构建器需要扩展 SolrQueryBuilder 或 SolrSpanQueryBuilder 类。示例 solrconfig.xml 片段:
<queryParser name="xmlparser" class="XmlQParserPlugin">
<str name="MyCustomQuery">com.mycompany.solr.search.MyCustomQueryBuilder</str>
</queryParser>