在 Solr 中搜索
Solr 为搜索提供了一组丰富而灵活的功能。为了理解这种灵活性的程度,从概述 Solr 搜索中涉及的步骤和组件开始会很有帮助。
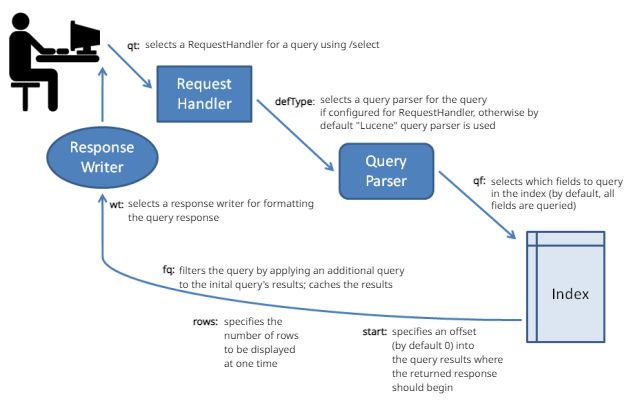
当用户在 Solr 中运行搜索时,搜索查询由请求处理程序处理。请求处理程序是一个 Solr 插件,它定义了 Solr 处理请求时要使用的逻辑。Solr 支持多种请求处理程序。一些设计用于处理搜索查询,而另一些则管理诸如索引复制之类的任务。
搜索应用程序默认选择特定的请求处理程序。此外,可以配置应用程序以允许用户覆盖默认选择,而偏好其他请求处理程序。
要处理搜索查询,请求处理程序会调用查询解析器,该解析器解释查询的术语和参数。不同的查询解析器支持不同的语法。Solr 的默认查询解析器称为标准查询解析器,或者更常见的是“lucene”查询解析器。Solr 还包括DisMax 查询解析器和扩展 DisMax (eDisMax) 查询解析器。
标准查询解析器的语法允许在搜索中具有更高的精度,但是 DisMax 查询解析器对错误的容忍度更高。DisMax 查询解析器旨在提供类似于 Google 等流行的搜索引擎的体验,这些搜索引擎很少向用户显示语法错误。扩展 DisMax 查询解析器是 DisMax 的改进版本,它处理完整的 Lucene 查询语法,同时仍然容忍语法错误。它还包括几个附加功能。
此外,所有查询解析器都接受常用查询参数。
查询解析器的输入可以包括:
-
搜索字符串,即要在索引中搜索的术语
-
用于微调查询的参数,通过增加特定字符串或字段的重要性,在搜索术语之间应用布尔逻辑或从搜索结果中排除内容
-
用于控制查询响应的呈现的参数,例如指定结果的呈现顺序或将响应限制为搜索应用程序的模式的特定字段。
搜索参数还可以指定过滤器查询。作为搜索响应的一部分,过滤器查询针对整个索引运行查询并缓存结果。由于 Solr 为过滤器查询分配了单独的缓存,因此策略性地使用过滤器查询可以提高搜索性能。
尽管名称相似,但查询过滤器与分析过滤器无关。过滤器查询在搜索时针对索引中已有的数据执行查询,而分析过滤器(如分词器)则按照指定的规则解析内容以进行索引。
搜索查询可以请求在搜索响应中突出显示某些术语;也就是说,选定的术语将以彩色框显示,以便它们在搜索结果的屏幕上“跳出”。高亮显示可以更轻松地在搜索返回的长文档中查找相关段落。Solr 支持多词高亮显示。Solr 包含一组丰富的搜索参数,用于控制术语的高亮显示方式。
还可以将搜索响应配置为包含具有突出显示文本的代码段(文档摘录)。
为了帮助用户精确定位他们正在寻找的内容,Solr 支持两种特殊的搜索结果分组方式,以帮助进一步探索:分面和聚类。
分面是将搜索结果按照类别(基于索引术语)进行排列。在每个类别中,Solr 会报告相关术语的命中次数,这被称为分面约束。分面使用户可以轻松地在电影网站和产品评论网站等具有许多类别和类别中有很多项目的网站上浏览搜索结果。
下面的屏幕截图显示了 CNET 网站(CBS Interactive Inc.)分面的一个示例,该网站是第一个使用 Solr 的网站。
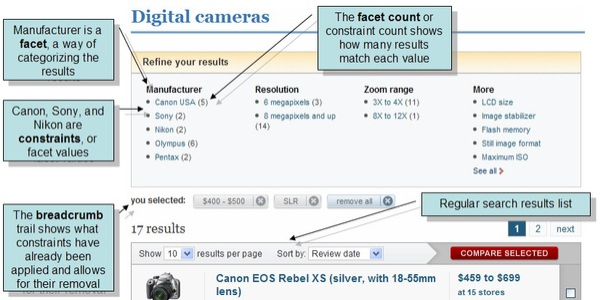
分面利用在索引搜索应用程序时定义的字段。在上面的示例中,这些字段包括用于描述数码相机的有用信息类别:制造商、分辨率和变焦范围。
聚类是在执行搜索时,而不是在索引内容时,根据发现的相似性对搜索结果进行分组。聚类的结果通常缺乏在分面搜索结果中发现的整齐的层次结构,但聚类仍然很有用。它可以揭示搜索结果中意想不到的共性,并且可以帮助用户排除与他们真正搜索的内容无关的内容。
Solr 还支持一个名为MoreLikeThis的功能,使用户能够提交新的查询,这些查询侧重于先前查询中返回的特定术语。MoreLikeThis 查询可以利用分面或聚类来为用户提供额外的帮助。
一个名为响应写入器的 Solr 组件管理查询响应的最终呈现。Solr 包括各种响应写入器,包括XML 响应写入器和JSON 响应写入器。
下图总结了搜索过程的一些关键要素。